

Data warehouses are struggling to keep up. As companies grow, a single centralized team managing all data creates delays, quality issues, and frustrated business users waiting for insights. Research from McKinsey shows that poor data quality costs organizations an average of $15 million annually, while centralized data teams create bottlenecks that slow decision-making. This is where Snowflake Data Mesh offers a solution. Instead of one team controlling everything, data mesh architecture distributes data ownership to domain teams who know their data best.
Think of it like moving from a single restaurant kitchen serving everyone to food courts where each vendor specializes in what they do well. Snowflake’s platform makes this shift practical by providing secure sharing, automated governance, and flexible compute that lets different teams work independently without copying data.
Organizations using data mesh architecture report faster time to insights and better data quality because people closest to the data are responsible for it. Whether you’re in retail tracking customer behavior, healthcare managing patient records, or finance ensuring compliance, Snowflake data mesh architecture helps break down silos while keeping security intact.
What is Snowflake Data Mesh?
Data mesh represents a fundamental rethinking of how organizations handle data at scale. Rather than funneling everything through a central data team, this approach treats data as products owned by business domains. Each business unit owns and manages their data as products.
Marketing owns customer data, sales owns pipeline data, and operations owns logistics data instead of everything sitting in one warehouse. Domains treat their data like any product with quality standards, documentation, and user support. This means thinking about who uses the data and making sure it meets their needs consistently. Teams can access and publish data without waiting for central IT. The platform provides tools for discovery, quality checks, and governance that anyone can use without specialized training.
The architecture relies on federated computational governance where policies are set centrally but executed at the domain level. Security rules, privacy standards, and compliance requirements apply everywhere but domains implement them in ways that fit their needs. Snowflake provides the technology foundation with secure sharing, automated governance, and zero-copy architecture that makes data mesh practical rather than just theory about organizational structure.
This combination of decentralized ownership with centralized policy enforcement creates a balance between autonomy and control that traditional data warehouses cannot achieve.
Why Snowflake Is Ideal for Building a Data Mesh
Snowflake’s architecture aligns naturally with data mesh principles because it was built for separation of storage and compute from the start. This makes domain independence possible without data duplication.
Aligns With Mesh Principles
The platform supports decentralized ownership while maintaining centralized governance through features like secure views, dynamic masking, and role-based access that work across organizational boundaries without creating silos.
Multi-Cloud and Multi-Region
Domains can run on AWS, Azure, or Google Cloud based on their needs. Data stays where regulations require while teams share across regions and clouds using Snowflake’s replication features.
Unified All-Workload Platform
One platform handles data warehousing, data lakes, data engineering, data science, and application development. Domains don’t need different tools for different workloads which reduces complexity and cost.
Elastic Domain Workloads
Each domain scales compute independently. Marketing can spin up large clusters for campaign analysis while finance runs steady queries without affecting each other. Snowflake’s pricing model ensures organizations only pay for the compute and storage they actually use, providing cost transparency and avoiding overprovisioning.
Secure Sharing, No ETL
Domains share live data without copying or moving it. Research from Forrester indicates that data engineers spend 30-50% of their time on ETL processes, and Snowflake’s zero-copy architecture eliminates these processes that introduce delays and increase costs.
Snowflake Features That Enable Data Mesh
Specific Snowflake capabilities make data mesh architecture practical by solving technical challenges around sharing, governance, processing, and discovery that would otherwise require custom development.
1) Snowflake Secure Data Sharing and Snowgrid
This foundation enables the entire mesh approach by allowing domains to share data without creating copies or compromising security controls. These Snowflake capabilities make it possible to maintain data integrity and enforce governance while enabling real-time collaboration across multiple domains.
Live Data Sharing
Consumers see updates instantly without waiting for batch processes. Snowflake data integration ensures that when a source domain updates customer records, all consuming domains automatically access the latest information without custom pipelines.
Zero-Copy Architecture
Sharing happens through metadata pointers rather than duplicating data. This cuts storage costs and eliminates version control problems where different teams work with different copies of the same information.
Cross-Region Governance
Policies follow data across geographic boundaries. A European domain sharing with US teams maintains GDPR controls automatically without manual policy duplication or risk of inconsistent protection.
Multi-Cloud Access
Teams on different cloud providers access the same data. Your AWS-based sales team and Azure-based marketing team share customer data without cloud-to-cloud data transfers or compatibility issues.
2) Snowflake Marketplace and Native Apps
These features transform internal data sharing into a product catalog where domains publish and discover data just like external software marketplaces.
Publish Shareable Assets
Domains package data products with documentation and quality metrics. The finance domain publishes monthly revenue data with schema definitions, update schedules, and contact information for questions.
Consume Domain Data
Users browse and request access to data products across the organization. Instead of emailing requests and waiting for custom data extracts, teams find and subscribe to products themselves.
Build Internal Apps
Domains create applications that run where the data lives. A customer service domain builds a support ticket analyzer that processes data in place without extracting sensitive customer information.
Domain-Focused Solutions
Teams package reusable analytics as Snowflake Native Apps. The supply chain domain creates a demand forecasting app that other domains use without learning the underlying data science.
3) Snowflake Data Catalog and Object Tagging
Discovery and governance at scale require automated metadata management that works across hundreds of data products from dozens of domains.
Automatic Metadata Management
Snowflake extracts and maintains metadata about tables, columns, and relationships without manual documentation. Users search for “customer email” and find all relevant data products across domains automatically.
Compliance Tagging Support
Tags mark sensitive data for automated policy enforcement. Tagging columns as PII triggers masking rules automatically without developers remembering to apply protections in every query.
Governance Enforcement Tools
Policies attach to tags rather than individual objects. Adding a new table with PII tags automatically applies encryption, access controls, and audit logging without manual configuration.
Track Data Lineage
The system shows where data comes from and where it flows. Compliance teams trace customer data from source systems through transformations to reports proving proper handling for audits.
4) Snowpark and Native Processing
Domain teams need to process data using languages and tools they already know without learning new platforms or moving data to specialized systems.
Domain-Specific Pipelines
Teams build data transformations in Python or Java instead of only SQL. Data scientists create feature engineering pipelines using familiar pandas and scikit-learn libraries that run at scale.
Python, SQL, Java
One platform supports multiple languages based on team skills. Business analysts use SQL for reports while engineers use Python for machine learning without switching platforms or copying data.
Custom Compute Logic
Complex transformations run where data lives rather than extracting to external systems. Domains apply industry-specific calculations and business rules that would be difficult or slow in pure SQL.
In-Database Processing
User-defined functions and stored procedures execute inside Snowflake. This eliminates network latency and data transfer costs associated with pulling data to external applications for processing.
Comparing Data Mesh: Snowflake vs Others
Different platforms take varying approaches to data mesh implementation. Understanding these differences helps organizations choose the right foundation for their architecture.
| Feature | Snowflake | Databricks | AWS Lake Formation | Microsoft Fabric |
| Zero-Copy Sharing | Native across clouds | Limited to Delta Sharing | Within AWS only | Within Azure only |
| Multi-Cloud Support | AWS, Azure, GCP native | Requires separate deployments | AWS only | Azure only |
| Governance Model | Centralized policies, federated execution | Data-centric governance | IAM-based controls | Unified governance |
| Data Product Catalog | Snowflake Marketplace | Delta Sharing catalog | AWS Glue Data Catalog | OneLake catalog |
| Processing Languages | SQL, Python, Java, Scala | Python, SQL, R, Scala | Python, SQL via Athena | SQL, Python, Spark |
| Learning Curve | Lower for SQL users | Steeper for non-engineers | Moderate with AWS knowledge | Moderate for Microsoft users |
| Cost Model | Per-second compute | Per-node clusters | Pay per query | Capacity-based |
| Domain Isolation | Account or database level | Workspace separation | AWS account boundaries | Workspace boundaries |
Building a Data Mesh on Snowflake: Step-by-Step
Implementation requires careful planning and execution across organizational and technical dimensions. These steps provide a roadmap from concept to production.
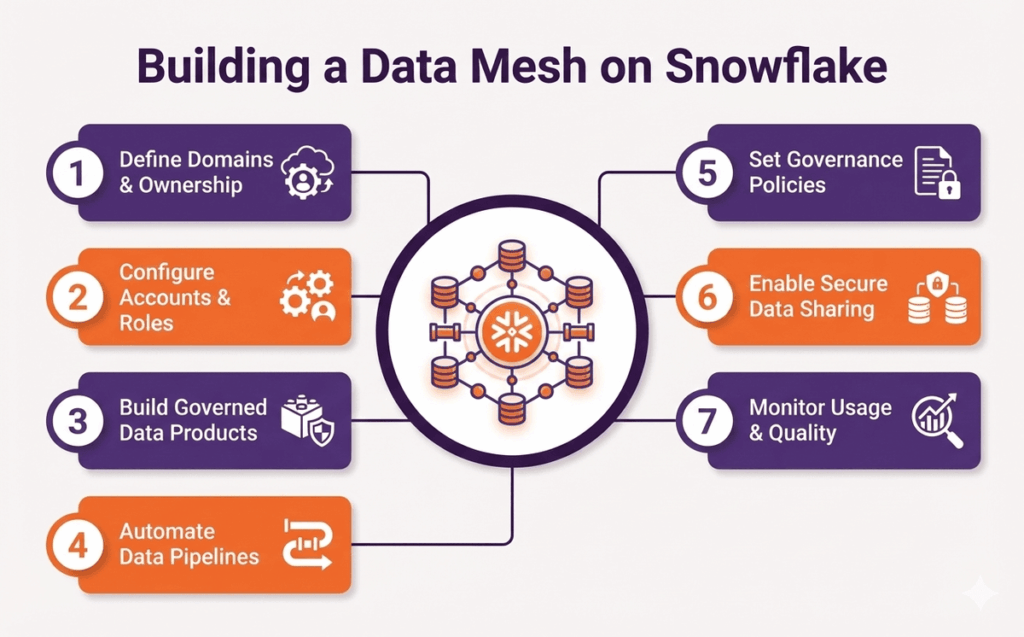
Step 1: Define Domains and Ownership
Start by mapping business capabilities to data domains. Identify natural ownership boundaries like product lines, customer segments, or geographic regions where teams already have business responsibility and domain knowledge.
Step 2: Configure Accounts and Roles
Set up Snowflake accounts for major domains or use databases within accounts for smaller organizations. Create role hierarchies that reflect domain ownership while maintaining security separation between teams.
Step 3: Build Governed Data Products
Each domain designs data products with clear schemas and quality standards. Document what the data represents, update frequency, quality checks, and who to contact for questions or issues.
Step 4: Automate Data Pipelines
Use Snowflake Tasks and Streams to automate data refreshes. Build pipelines that check data quality before publishing updates so consumers always receive validated, trustworthy data products. Snowflake connectors make it easy to integrate data from external sources directly into these pipelines, ensuring seamless ingestion across multiple systems.
Step 5: Establish Governance Policies
Define tagging standards for sensitive data and attach policies to tags. Set up masking rules, encryption requirements, and access controls that apply consistently across all domains.
Step 6: Enable Secure Data Sharing
Configure shares between domains using Snowflake’s native sharing features. Set up reader accounts for teams that don’t need full Snowflake access but need to consume specific data products.
Step 7: Monitor Usage and Quality
Track which data products get used and who’s consuming them. Monitor query performance, data freshness, and quality metrics to identify popular products and areas needing improvement.
Use Cases and Examples of Snowflake Data Mesh
Real-world applications demonstrate how different industries apply data mesh principles using Snowflake to solve specific business challenges.
1) Multi-Department Analytics
A technology company with product, engineering, sales, and support domains uses Snowflake data mesh to eliminate analytics bottlenecks. Each department owns their data and shares relevant products with others.
2) Retail Domain Data
Store operations, e-commerce, supply chain, and customer experience teams maintain separate domains. Inventory data flows from supply chain to stores and online channels without centralized data team involvement.
3) Financial Services Stewardship
Banks separate customer, account, transaction, and risk domains. Each maintains strict data quality standards while sharing through governed products that enforce compliance policies automatically through tagging.
4) Healthcare Data Products
Hospital systems organize clinical, operational, financial, and research domains. Patient data stays in clinical domains with secure sharing to research teams using de-identification policies attached to PII tags. Snowflake HIPAA compliance features ensure that sensitive patient data meets regulatory standards while enabling analytics and collaboration across departments.
5) SaaS Marketplace Delivery
Software vendors package customer usage analytics as data products. Clients access their data through Snowflake Marketplace without vendors building custom reporting infrastructure for each customer.
Benefits of Snowflake Data Mesh
Organizations adopting this architecture report multiple advantages that compound over time as more domains mature their data products.
1) Decentralized Data Ownership
Teams closest to data take responsibility for quality and availability. Marketing knows customer data better than a central team serving twenty departments so they produce better data products.
2) Reduced Data Bottlenecks
Domains serve themselves instead of waiting in central team queues. According to a study by Accenture, organizations adopting decentralized data architectures report up to 50% faster time-to-insight by eliminating centralized bottlenecks and empowering domain teams with direct data access.
3) Faster Analytics and Autonomy
Business users access data products directly without submitting requests. Analysts spend time analyzing rather than waiting for data extracts or explaining requirements to engineers who don’t understand business context. Snowflake reporting tools allow teams to generate real-time dashboards and insights directly from their domains, further reducing dependency on central IT and accelerating decision-making.
4) Improved Governance and Compliance
Automated policy enforcement reduces human error. Tags and roles ensure consistent security application across all domains without relying on manual processes that break as organizations scale.
5) Cost Transparency and Optimization
Each domain sees their compute costs separately. Finance tracks spending on financial analytics while marketing optimizes their campaign analysis costs without shared resource pool confusion.
Challenges and Limitations of Data Mesh on Snowflake
Implementation involves overcoming organizational and technical hurdles that require planning and commitment beyond technology deployment.
Organizational Readiness
Companies need mature data practices before attempting mesh architecture. Organizations without basic data quality processes or clear domain boundaries struggle because mesh amplifies existing problems across more independent teams.
Governance Model Required
Success depends on establishing federated governance before decentralizing. Without clear standards for tagging, quality, and documentation, domains create inconsistent products that reduce trust and limit reuse.
Risk of Inconsistency
Different domains may define metrics differently. Revenue calculated by finance might not match sales calculations if domains don’t coordinate on standard definitions for shared concepts.
Cultural Shift Needed
Teams must embrace product thinking about data. This requires changing from “provide whatever anyone asks for” to “maintain quality products for known use cases” which feels restrictive initially.
Domain Cost Management
Decentralized ownership can lead to uncontrolled spending. Domains need cost visibility and accountability frameworks to prevent compute waste when teams spin up resources without considering organizational budgets.
Best Practices for Implementing Snowflake Data Mesh
Following proven patterns increases success probability while avoiding common pitfalls that delay value realization or create technical debt.
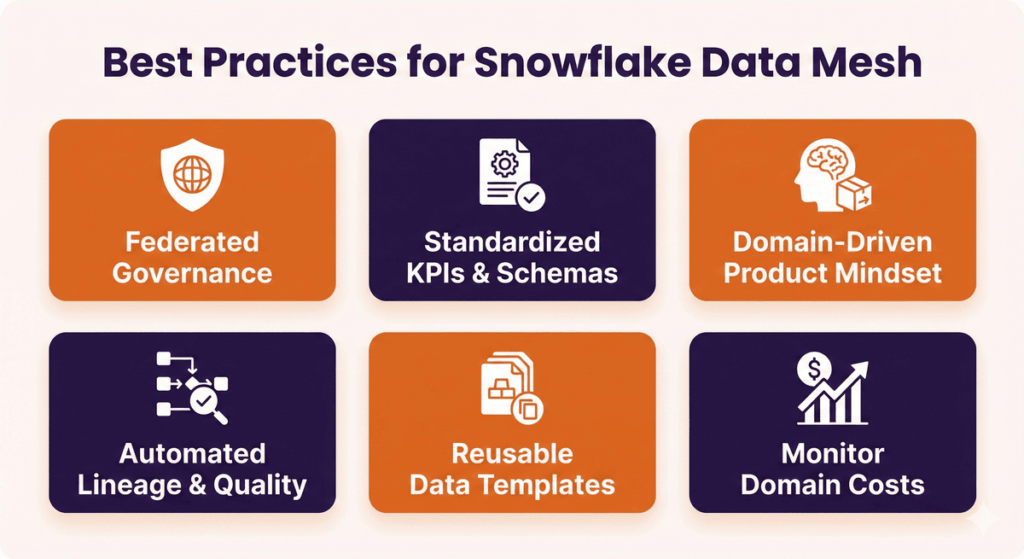
1) Federated Governance Model
Establish a governance council with domain representatives. This group sets policies collaboratively rather than central teams imposing rules that domains resist or find impractical for their specific needs. Snowflake modernization services can help design these councils and governance frameworks.
2) Standardize KPIs and Schemas
Agree on common definitions for shared business metrics. When multiple domains track customers or revenue, standardized calculations ensure consistent reporting across the organization.
3) Domain-Level Product Thinking
Train domain teams to think like product managers. Each data product needs an owner, roadmap, user documentation, and support model just like any software product customers depend on.
4) Automate Lineage and Quality
Implement automated data quality checks in pipelines. Use Snowflake’s built-in lineage tracking and add custom quality metrics that run automatically before publishing updates to data products.
5) Reusable Data Templates
Create templates for common data product patterns. Standard schemas for customer data, transaction data, or event logs help domains publish products faster with consistent structure.
6) Monitor Domain Cost
Implement cost allocation tags and regular reviews. Each domain should see their Snowflake spending monthly and optimize queries or compute resources that drive unnecessary costs.
Future Trends in Snowflake Data Mesh
The platform and architecture continue advancing as organizations learn from early implementations and technology capabilities expand.
Emerging Trends and Apps
More domains are publishing internal applications as Snowflake Native Apps. This trend moves beyond sharing raw data to sharing complete analytical solutions that embed domain expertise and business logic.
AI Workloads Support
Machine learning models are becoming data products themselves. Domains train models on their data and share predictions as products that other teams consume without understanding underlying algorithms. Snowflake’s AI Model capabilities allow these workloads to run efficiently within the platform, enabling seamless integration of predictive insights into everyday business operations.
Data Marketplace Evolution
Internal marketplaces are adding features from external ones like ratings and reviews. Organizations are tracking which data products get used most and retiring unpopular ones to focus resources on valuable assets.
Folio3 Solutions for Snowflake Data Mesh
Moving to data mesh architecture requires expertise beyond technology implementation. Folio3 Data Services brings deep experience helping organizations design and deploy Snowflake-based data mesh solutions.
1) Expert Consultation and Strategy
Our snowflake consulting experts assess your current data architecture and organizational structure to design a practical mesh implementation roadmap. We identify domain boundaries, prioritize initial domains, and plan governance models that fit your culture.
2) Implementation and Migration Services
We handle technical implementation from Snowflake account setup through data pipeline development. Our engineers build secure sharing configurations, automate data quality checks, and establish monitoring that ensures reliable data products.
3) Data Governance and Compliance
Folio3 implements tagging strategies, access controls, and audit logging that meet regulatory requirements. We design governance frameworks for healthcare, financial services, and other regulated industries requiring strict data stewardship.
4) Domain Data Products Development
Our team works with your domain experts to design and build initial data products. We establish patterns and templates that your teams replicate for additional products as the mesh architecture matures.
FAQs
What is a data mesh and how does Snowflake support it?
Data mesh is an organizational approach that decentralizes data ownership to business domains rather than centralizing it with one team. Snowflake supports this through secure data sharing, federated governance, and zero-copy architecture that lets domains share data without duplication.
How do Snowflake domains and data products work in a data mesh architecture?
Each domain owns specific data and publishes it as products through Snowflake shares. Other domains consume these products by accessing shared databases or schemas without copying data, while governance policies enforce consistent security across all products.
What are the benefits of implementing a Snowflake data mesh for enterprises?
Organizations gain faster analytics through reduced bottlenecks, better data quality from domain ownership, improved governance through automated policies, cost transparency by domain, and greater business user autonomy without sacrificing security.
How does Snowflake ensure data governance and security in a data mesh setup?
Snowflake uses centralized policies applied at the tag level that enforce consistently across domains. Features like dynamic data masking, row-level security, and audit logging work automatically on shared data without manual policy duplication.
Can Snowflake handle multi-cloud and cross-region data mesh deployments?
Yes, Snowflake runs natively on AWS, Azure, and Google Cloud. Data replication features enable sharing across regions and clouds while maintaining governance policies, letting domains choose infrastructure based on their requirements.
What are common challenges organizations face when building a data mesh on Snowflake?
Main challenges include organizational change management, establishing federated governance before decentralizing, preventing metric inconsistency across domains, shifting to product thinking about data, and managing costs when domains scale independently.
How does Snowpark help automate domain-specific pipelines in Snowflake data mesh?
Snowpark lets domains build data pipelines in Python, Java, or Scala rather than only SQL. Teams create custom transformations using familiar tools that execute inside Snowflake without extracting data to external systems.
What are real-world use cases of Snowflake data mesh in industries like retail and healthcare?
Retailers use data mesh to separate store operations, e-commerce, supply chain, and customer domains. Healthcare organizations divide clinical, operational, financial, and research domains while maintaining HIPAA compliance through automated governance.
How does Snowflake Marketplace enable sharing and monetizing data products in a data mesh?
Marketplace provides a catalog where domains publish data products with documentation and access controls. Internal teams discover and subscribe to products just like external software, and organizations can extend this to monetize data externally.
Conclusion
Snowflake Data Mesh transforms how organizations manage data at scale by combining decentralized ownership with centralized governance. The architecture eliminates bottlenecks while improving quality because teams closest to data take responsibility for it.
Success requires more than technology though. Organizations need clear domain boundaries, federated governance models, and cultural shifts toward product thinking. Snowflake provides the platform with secure sharing, automated governance, and flexible compute that makes data mesh practical. As companies generate more data across more teams, traditional centralized approaches stop working. Data mesh offers a path forward that scales with organizational complexity while maintaining security and compliance.
Folio3 Data Services specializes in helping organizations navigate this transition. Our experts design practical mesh architectures aligned with your business structure, implement Snowflake-based solutions, and establish governance frameworks that balance autonomy with control. Whether you’re starting fresh or modernizing existing data infrastructure, Folio3 brings the experience to make your data mesh implementation successful. Contact us to discuss how Snowflake Data Mesh can solve your data challenges.



