

Every day, businesses create and collect an enormous amount of information that doesn’t fit neatly into traditional rows and columns. This type of data, often called unstructured data, includes everything from emails and documents to videos and social media posts. The sheer volume is staggering; estimates suggest that over 80% of all data generated today is unstructured.
Effectively managing this vast ocean of information is a key challenge for organizations looking to stay competitive. By 2025, the global datasphere is projected to reach 175 zettabytes, with a significant portion remaining unstructured and ripe for analysis (Source: Seagate, IDC).
Without proper unstructured data management, valuable insights remain hidden, compliance risks increase, and operational efficiency suffers. This guide will help you understand what unstructured data is, why it’s growing so fast, and why many companies find it hard to handle. We’ll then provide a practical framework, essential tools, and best practices to help you take control and use this data to your advantage.
What is Unstructured Data?
Unstructured data is information that does not have a predefined data model or is not organized in a pre-defined manner. It doesn’t reside in fixed fields within a database or a table. Instead, it comes in various forms and typically does not fit neatly into relational database structures. Think of it as information that needs context and interpretation to be understood.
Why Unstructured Data Management is Critical Today
Managing unstructured data effectively is no longer optional; it is a necessity for modern businesses to thrive. The vast majority of new data being created falls into this category, and within it lies untapped potential for insight and innovation. Without a clear strategy, organizations risk losing out on competitive advantages, facing compliance challenges, and making less informed decisions.
Turning Data into Strategic Insights
The information within emails, customer reviews, and sensor data holds clues about market trends, customer sentiment, and operational efficiencies. Properly managing this data allows businesses to analyze it, uncover patterns, and gain insights that are impossible to find in structured databases alone. This leads to better product development and smarter business strategies.
Enhancing Operational Efficiency
Disorganized unstructured data can create inefficiencies, as employees spend too much time searching for information or recreating lost data. A robust system that combines data management and engineering centralizes these resources, making them easily searchable and accessible. This streamlines workflows, reduces redundant efforts, and improves overall productivity across departments.
Meeting Compliance and Regulatory Demands
Many industries face strict regulations regarding data retention, privacy, and security, especially for sensitive documents, contracts, and communications. Unstructured data, if not managed, classified, and secured correctly, can become a major compliance headache. Proper management ensures audit trails, data protection, and adherence to legal requirements.
Improving decision-making processes
When leaders have access to a complete picture of information – both structured and unstructured – they can make more informed and strategic decisions. Analyzing customer feedback, market reports, and internal communications alongside sales figures provides a richer context. This comprehensive view minimizes guesswork and strengthens strategic planning.
Supporting artificial intelligence and machine learning
AI and machine learning models thrive on data, and unstructured data provides a rich source for training these systems. From natural language processing of text to computer vision for images, effective management prepares this data for AI ingestion.
When organizations enable data integration in real-time, these models receive fresher, more accurate information, enhancing advanced analytics, predictive modeling, and automation capabilities that drive innovation.
Types of Unstructured Data (With Real-world Examples)
Unstructured data comes in many forms, reflecting the diverse ways people and systems interact and generate information. Recognizing these types helps in understanding the unique challenges each presents for management and analysis. From everyday communications to specialized machine outputs, understanding these categories is the first step toward effective control.
Textual Data (Documents, Chat Logs, Social Posts)
This category includes all forms of written content that do not adhere to a rigid format. Examples are plentiful and common in daily business operations. Think of email bodies, Word documents, PDF reports, customer service chat transcripts, social media comments, blog posts, and research papers. This data often contains rich qualitative insights.
Media Data (Audio, Images, Videos)
Media files are highly prevalent and carry vast amounts of information in non-textual formats. Images include photos, scans of documents, medical imagery like X-rays, and security camera footage. Audio data comprises voice recordings, call center interactions, and podcasts. Video files include surveillance footage, training videos, and customer testimonials.
Machine-Generated Data (Sensor Logs, IoT Device Data)
Modern technology, especially in industrial and connected environments, produces a constant stream of unstructured data. This includes log files from servers and applications, sensor data from IoT devices like smart meters or manufacturing equipment, satellite imagery, and web server logs. This data is critical for monitoring, diagnostics, and predictive maintenance.
Metadata & System Logs
While metadata technically describes other data, it often exists in an unstructured or semi-structured format outside of a formal database. Examples include file creation dates, author names, modification histories, and application event logs. System logs track user activities, errors, and system performance, providing crucial information for security and troubleshooting.
Structured vs. Unstructured Data Management: Side-by-Side Overview
Understanding the differences between structured and unstructured data, and their respective management approaches, is fundamental. Structured data is like a neatly organized library, while unstructured data is more like a vast collection of diverse artifacts. Each requires a distinct set of tools and strategies to ensure efficient storage, retrieval, and analysis.
| Feature | Structured Data Management | Unstructured Data Management |
| Definition | Data that follows a predefined schema; stored in rows and columns. | Data without a predefined schema; not organized in tables. |
| Examples | Customer names, addresses, product IDs, transaction records. | Emails, documents, images, videos, audio files, social media posts, sensor data. |
| Storage | Relational databases (RDBMS), data warehouses. | Data lakes, cloud storage, NoSQL databases, file systems. |
| Querying | SQL; precise and fast. | Content search, metadata search, AI-driven analysis, NLP. |
| Scalability | Often vertical; can be complex. | Highly scalable; horizontal scaling with distributed storage. |
| Tools | ETL tools, database management systems (DBMS). | Hadoop, Spark, AI/ML platforms, data lakes, ECM systems. |
| Analysis | BI tools, reporting, statistical analysis. | Text analytics, NLP, computer vision, sentiment analysis, predictive modeling. |
| Challenges | Rigid schema, complex joins, limited flexibility. | Large volume, diverse formats, unstructured, hard to search/analyze. |
| Security | Table/row-level security, ACLs. | Object-level security, encryption, access controls, DLP. |
| Use Cases | Financial reporting, CRM, inventory management, transactional systems. | Customer service analytics, fraud detection, medical imaging, compliance, R&D. |
The Unstructured Data Management Framework: 8 Steps Guide
Effectively managing unstructured data requires a systematic approach, moving beyond simple storage to full lifecycle governance. This framework outlines the key stages, from initial identification to continuous oversight, ensuring that your organization can extract value and mitigate risks. Each step builds upon the last, forming a robust strategy for handling diverse information.
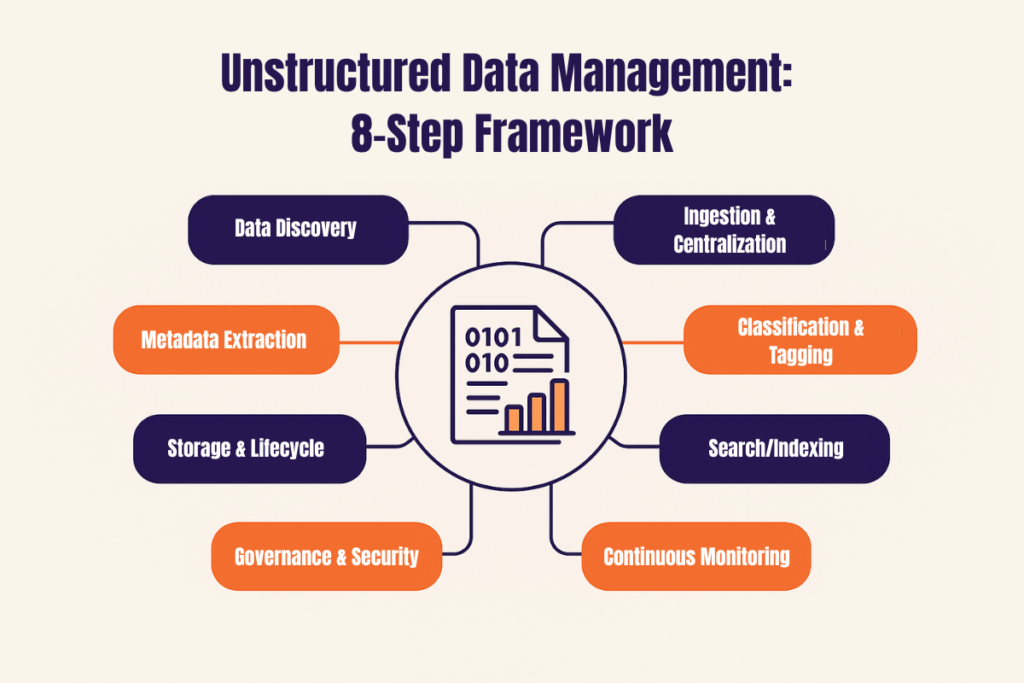
Step #1: Data discovery
The first step is to identify where unstructured data resides across your organization. This involves scanning network drives, cloud storage, email servers, and collaboration platforms. Data discovery tools help to locate files, understand their types, and identify potential risks or compliance issues. Knowing what you have and where it is is foundational.
Step #2: Ingestion & centralization
Once discovered, data needs to be brought into a centralized system where it can be managed. This involves processes for ingesting data from various sources into a data lake or object storage. Implementing multiple layers of data ingestion architecture ensures that data flows efficiently from source to storage, handling batch and real-time streams while maintaining quality, security, and scalability.
Centralization breaks down data silos, making the data accessible for subsequent processing and analysis. Secure and efficient transfer is key here.
Step #3: Metadata extraction
Metadata—data about data—is crucial for making unstructured content searchable and understandable. This step involves automatically extracting attributes like author, creation date, keywords, and content summaries. Advanced tools can also extract entities, topics, and sentiments, enriching the data for better organization and retrieval.
Step #4: Classification & tagging
With metadata extracted, the next step is to classify and tag the data based on its content, sensitivity, and business relevance. This can be done manually or, more effectively, using AI-powered tools that automatically categorize documents. Proper classification enables easier search, applies appropriate access controls, and supports compliance efforts.
Step #5: Storage & lifecycle
Choosing the right storage solution, such as cloud object storage or a data lake, is essential for scalability and cost-effectiveness. This step also involves defining data lifecycle policies. This means deciding how long data should be kept, when it should be moved to colder storage tiers, and when it can be securely archived or deleted to manage costs and compliance.
Step #6: Search/indexing
To make unstructured data useful, it must be easily searchable. This step involves indexing the data, creating a searchable catalog based on extracted metadata and content. Powerful search engines allow users to quickly find specific documents, images, or videos, reducing time spent looking for information and improving productivity.
Step #7: Governance & security
Implementing robust governance policies ensures data integrity, compliance, and responsible usage. This includes defining access controls, encryption, and data loss prevention strategies. Security measures protect sensitive information from unauthorized access, while governance ensures adherence to internal policies and external regulations.
Step #8: Continuous monitoring
Unstructured data environments are dynamic, with new data constantly being generated and existing data being accessed or modified. Continuous monitoring involves regularly auditing data, tracking usage patterns, and ensuring compliance with policies. This proactive approach helps identify and address potential issues before they become serious problems.
Tools & Technologies for Unstructured Data Management
The right tools are essential for effectively managing the complexity and volume of unstructured data. These technologies range from robust storage solutions that can handle massive files to intelligent processing engines that extract meaning. Understanding the landscape of available tools helps organizations build a resilient and efficient data management system.
Storage & Platforms
Choosing the right foundation for your unstructured data is critical for scalability, accessibility, and cost. Cloud-based object storage services are dominant here, offering elastic capacity and high availability. They provide the backbone for data lakes where raw, unstructured data can be stored before processing.
AWS S3
Amazon Simple Storage Service (S3) is an industry-leading object storage service offering high scalability, data availability, security, and performance. It is ideal for storing any type of unstructured data, from backups and archives to big data analytics. S3 also supports various storage classes for cost optimization.
Azure Data Lake
Azure Data Lake is a comprehensive platform designed for big data analytics, offering limitless storage capacity for all types of data. It integrates with other Azure services for processing and analysis.
Organizations looking to migrate from data warehouse to lakehouse can leverage Azure Data Lake Storage Gen2, which combines the best features of Azure Blob Storage with a hierarchical file system for faster analytics and seamless integration with downstream processing tools.
Google Cloud Storage
Google Cloud Storage is a scalable, secure, and durable object storage service for immutable data. It offers various storage classes tailored for different access frequencies, from frequently accessed hot data to long-term archives. It integrates seamlessly with Google Cloud’s powerful analytics and AI tools.
Snowflake Unstructured File Support
Snowflake, known for its data warehousing capabilities, has expanded to offer native support for unstructured data files. This allows users to store, manage, and process various file types directly within Snowflake, leveraging its powerful engine for analysis and integration with structured data.
Organizations planning a Snowflake implementation can now handle both structured and unstructured data in a single platform, simplifying their analytics workflows and improving efficiency.
Processing & AI Extraction Tools
Simply storing unstructured data isn’t enough; organizations need tools to extract valuable information and insights from it. AI data extraction software and machine learning play a pivotal role here, automating tasks like text recognition, image analysis, and entity extraction, transforming raw data into actionable intelligence.
AWS Textract
AWS Textract is a machine learning service that automatically extracts text, handwriting, and data from scanned documents. It goes beyond simple optical character recognition (OCR) to identify fields, tables, and structured information within unstructured forms and documents, enabling faster processing.
Azure Computer Vision
Azure Computer Vision is an AI service that analyzes images and returns information about their visual features. It can identify objects, faces, text, and categorize images. This is invaluable for managing image and video data, enabling content moderation, search by visual characteristics, and automated tagging.
GCP Document AI
Google Cloud Document AI is a specialized platform for processing documents of various types, including invoices, receipts, and contracts. It uses machine learning to understand document structure and extract key data, automating document processing workflows and reducing manual effort.
Open-source: Apache Tika, ElasticSearch, LangChain tools
Open-source tools provide flexible and customizable options. Apache Tika extracts text and metadata from over a thousand different file types. ElasticSearch is a powerful search and analytics engine often used for indexing and searching unstructured data. LangChain tools facilitate building applications with large language models, enabling advanced text processing and AI interactions.
Governance & Cataloging
Once data is stored and processed, managing its lifecycle, ensuring compliance, and making it discoverable are crucial. Data governance and cataloging tools provide the necessary framework for oversight, access control, and a unified view of all data assets, both structured and unstructured.
Collibra
Collibra is a data governance platform that helps organizations understand and trust their data. It provides data cataloging, data quality, and data privacy capabilities. For unstructured data, it helps in documenting data assets, defining ownership, and ensuring compliance through policy enforcement.
Alation
Alation offers a data catalog that helps users discover, understand, and trust data. It uses machine learning to profile data, recommend relevant data assets, and provide a collaborative environment for data users. It helps in making unstructured data more discoverable and understandable across the enterprise.
Informatica
Informatica provides a comprehensive suite of data management solutions, including data integration, data quality, and data governance. Its tools can help in profiling, classifying, and governing unstructured data, ensuring it meets quality standards and compliance requirements throughout its lifecycle.
Databricks Unity Catalog
Databricks Unity Catalog offers a unified governance solution for data and AI on the lakehouse. It provides a single interface to manage data, metadata, and permissions across various data assets, including unstructured files. Its architecture also supports modern data engineering AI integration, helping teams centralize control, streamline governance, and maintain visibility across diverse data types.
Practical Use Cases of Unstructured Data Management
The ability to effectively manage unstructured data unlocks significant value across various industries and business functions. By transforming raw information into actionable insights, organizations can enhance customer experiences, optimize operations, and drive innovation. These examples highlight the tangible benefits of a robust unstructured data strategy.
Customer Experience Analytics
By analyzing customer emails, support chat logs, social media comments, and call recordings, businesses can gain a deeper understanding of customer sentiment, pain points, and preferences. This allows for proactive customer service, personalized marketing campaigns, and product improvements tailored to user needs, ultimately enhancing the overall customer journey.
Healthcare Data Management
Healthcare organizations deal with vast amounts of unstructured data, including doctor’s notes, medical images (X-rays, MRIs), patient records, and research papers. Effective management enables faster diagnosis, better treatment planning, improved patient outcomes, and supports medical research by making this critical information searchable and analyzable.
Strong practices in data processing in healthcare help streamline how this information is organized and interpreted, ultimately improving clinical decision-making and operational efficiency.
eCommerce Data Insights
In eCommerce, unstructured data like product reviews, customer feedback, competitor analyses, and website clickstreams provide rich insights. Managing this data helps businesses identify popular products, understand purchasing patterns, optimize product descriptions, and personalize recommendations, leading to increased sales and customer loyalty.
Finance Document Processing
Financial institutions handle countless unstructured documents such as contracts, loan applications, financial statements, and regulatory reports. Automating the extraction of key information from these documents reduces manual errors, speeds up processing times, improves compliance audits, and enhances fraud detection capabilities, boosting efficiency and security.
Manufacturing & IoT data
Modern manufacturing relies heavily on data from IoT sensors, machine logs, and quality control reports. Managing this continuous stream of unstructured data allows for predictive maintenance, optimizing production processes, identifying defects early, and improving overall operational efficiency, leading to cost savings and higher product quality.
Key Challenges in Unstructured Data Management
While the benefits of mastering unstructured data are clear, organizations often encounter significant hurdles in their efforts. The sheer volume, diverse formats, and inherent lack of structure present complex problems that require thoughtful solutions. Addressing these challenges is crucial for a successful data management strategy.
Siloed Storage Systems
Unstructured data often gets stored in various isolated systems across an organization, such as individual hard drives, departmental network shares, cloud services, and email servers. These silos make it incredibly difficult to get a complete view of the data, leading to duplication, inconsistent versions, and missed opportunities for analysis. Many organizations work with data warehousing consultants to break down these silos and design centralized architectures that improve accessibility and governance.
Limited Searchability
Traditional search methods struggle with unstructured data because it lacks predefined categories or indexes. Finding specific information within millions of documents, images, or audio files can be like finding a needle in a haystack. This severely hampers productivity and limits the ability to extract timely insights.
Data Quality Gaps
Unlike structured data, which often has validation rules, unstructured data can suffer from poor quality, including inconsistencies, inaccuracies, or incomplete information. Extracting meaningful insights from messy, redundant, or outdated unstructured data is challenging and can lead to flawed conclusions.
Security & Compliance Risks
Unstructured data often contains sensitive information, such as personal identifiable information (PII), intellectual property, or confidential business details. Without proper controls, this data is vulnerable to breaches. Furthermore, complying with data privacy regulations (like GDPR or CCPA) becomes complex when sensitive data is scattered and unclassified.
Scalability Limitations
The volume of unstructured data is growing exponentially. Traditional storage and processing systems often struggle to scale effectively to accommodate this rapid growth. Managing terabytes, and eventually petabytes, of diverse file types without breaking the budget or sacrificing performance is a constant challenge for many organizations.
Best Practices for Unstructured Data Management
Overcoming the challenges of unstructured data requires a strategic approach built on proven methods. Implementing best practices ensures that data is not only stored efficiently but also secured, discoverable, and valuable to the organization. These principles help transform a complex problem into a managed asset.
Clear Governance Model
Establish clear policies, roles, and responsibilities for data ownership, access, retention, and deletion. A well-defined governance model ensures that all unstructured data is handled consistently and compliantly. This framework guides decision-making and ensures accountability across the data lifecycle.
Standardize Metadata
Develop and enforce consistent metadata standards across all unstructured data types. Rich, standardized metadata—such as creation date, author, department, keywords, and security classification—is vital for making data discoverable, improving searchability, and enabling automated processing and analysis.
Scalable Cloud Storage
Leverage cloud object storage solutions (like AWS S3, Azure Data Lake, Google Cloud Storage) for their inherent scalability, cost-effectiveness, and durability. Implementing a robust big data architecture for processing data ensures that unstructured datasets of any size can be ingested, stored, and analyzed efficiently. Cloud storage can easily accommodate exponential data growth without significant upfront infrastructure investments and offers global accessibility for distributed teams.
AI-Powered Classification
Implement artificial intelligence and machine learning tools to automate the classification and tagging of unstructured data. AI can analyze content, extract entities, and assign categories with high accuracy, significantly reducing manual effort and improving the consistency and speed of data organization.
Automate Retention Policies
Define and automate data retention and disposition policies based on regulatory requirements, business value, and data sensitivity. Automated lifecycle management ensures that data is stored for the appropriate duration, moved to cost-effective storage tiers, and securely deleted when no longer needed, reducing storage costs and compliance risks.
Continuous Monitoring & Auditing
Regularly monitor data access, usage, and integrity. Implement auditing mechanisms to track who accessed what data, when, and from where. Continuous monitoring helps detect suspicious activities, ensures compliance with security policies, and provides valuable insights into data utilization patterns.
Secure Access Controls
Implement robust, granular access controls based on roles and least privilege principles. Ensure that only authorized personnel can access sensitive unstructured data. Utilize encryption both at rest and in transit, and consider data loss prevention (DLP) tools to prevent unauthorized sharing or exfiltration of critical information.
How to Choose the Right Unstructured Data Management Solution
Selecting the ideal unstructured data management solution is a critical decision that impacts an organization’s efficiency, security, and ability to derive insights. It’s not a one-size-fits-all choice, and requires careful consideration of current needs, future growth, and specific business objectives. A thoughtful evaluation process will lead to the best fit.
Criteria: Scalability, Cost, Governance, AI Integration
When evaluating solutions, consider how well they can grow with your data volume (scalability), the total cost of ownership including storage and processing (cost), their ability to enforce policies and ensure compliance (governance), and their built-in or integrable AI capabilities for classification and extraction (AI integration). These factors are paramount.
Checklist to Evaluate Vendors
Create a detailed checklist covering aspects like ease of integration with existing systems, supported data formats, security features, reporting and auditing capabilities, vendor support, and user interface intuitiveness. Ask for case studies, conduct proof-of-concept trials, and compare performance benchmarks to make an informed decision.
Cloud vs On-Premise Considerations
Decide whether a cloud-based, on-premise, or hybrid solution best suits your needs. Cloud solutions offer flexibility, scalability, and reduced infrastructure costs, but require strong internet connectivity. On-premise solutions provide maximum control and can be preferred for highly sensitive data, but demand significant upfront investment and maintenance.
Folio3: Intelligent Data Management Solutions
Folio3 offers robust data management solutions designed to help businesses tame their unstructured data challenges. We provide comprehensive services ranging from data strategy and architecture design to implementation and ongoing support.
Our approach focuses on creating scalable, secure, and intelligent data environments that align with your specific business goals. We leverage leading cloud platforms and advanced AI/ML capabilities to transform your unstructured data into a valuable asset.
Whether you need assistance with data discovery, building a data lake, automating classification, or ensuring compliance, Folio3 brings expert knowledge and practical solutions to streamline your unstructured data management journey. Our tailored solutions empower you to unlock insights, improve operational efficiency, and drive innovation, ensuring your data strategy is future-ready and impactful.
FAQs
What is an example of unstructured data?
Common examples of unstructured data include emails, Microsoft Word documents, PDF files, images (like photos or scanned documents), video recordings, audio files (such as call center recordings), social media posts, and sensor data from IoT devices.
What is the best way to manage unstructured data?
The best way to manage unstructured data involves a comprehensive strategy that includes data discovery, centralized storage (like data lakes), metadata extraction, AI-powered classification and tagging, automated retention policies, robust security controls, and continuous monitoring.
What tools are used for unstructured data management?
Tools include cloud object storage services (AWS S3, Azure Data Lake, Google Cloud Storage), data processing and AI extraction tools (AWS Textract, Azure Computer Vision, GCP Document AI), and data governance and cataloging platforms (Collibra, Alation, Databricks Unity Catalog). Open-source options like Apache Tika and ElasticSearch are also used.
Why is unstructured data difficult to manage?
Unstructured data is difficult to manage due to its sheer volume, diverse formats, lack of a predefined structure, difficulty in searching and indexing, inherent data quality challenges, and the complexities involved in ensuring its security and compliance across various storage locations.
What industries rely most on unstructured data analytics?
Industries that heavily rely on unstructured data analytics include healthcare (patient records, medical images), finance (contracts, reports, customer communications), retail/eCommerce (customer reviews, social media sentiment), manufacturing (IoT sensor data, machine logs), and customer service (chat logs, call recordings).
What is the difference between structured and unstructured data?
Structured data fits into a predefined data model, like tables in a relational database, making it easy to query and analyze with SQL. Unstructured data lacks such a model, existing in freeform text, media, or logs, and requires more advanced tools like AI/ML for extraction and analysis.
How do organizations process unstructured data for AI?
Organizations process unstructured data for AI by first ingesting it into a data lake, then using AI tools for metadata extraction, natural language processing (NLP) for text, computer vision for images/videos, and sentiment analysis. This processed, labeled data is then used to train and refine AI models.
How does AI help in classifying, tagging, and analyzing unstructured data automatically?
AI uses machine learning algorithms to automatically identify patterns, extract entities, and categorize unstructured data. For example, NLP can classify documents by topic, computer vision can tag images with detected objects, and sentiment analysis can gauge the tone of customer feedback, significantly automating organization and analysis.
How can organizations implement best practices to automate unstructured data management?
Organizations can automate by leveraging cloud-based platforms for scalable storage, deploying AI/ML tools for automated classification and metadata extraction, implementing data lifecycle management policies for automated retention, and using data governance platforms for policy enforcement and monitoring.
Can unstructured data be integrated with structured data for advanced analytics and AI models?
Yes, integrating unstructured and structured data is crucial for advanced analytics and AI. Data lakes and lakehouse architectures facilitate this by providing a unified platform. Processed unstructured data, enriched with metadata, can then be joined with structured data in data warehouses for more comprehensive analysis and robust AI model training.
Conclusion
Mastering unstructured data management is no longer a technical challenge confined to IT departments; it’s a strategic imperative for every forward-thinking organization. The ability to effectively discover, store, process, and analyze the vast amounts of information locked away in documents, media, and logs can be a significant differentiator.
By adopting a systematic framework, leveraging appropriate tools, and committing to best practices, businesses can transform their data chaos into a competitive advantage. This guide provides a clear roadmap to navigate the complexities, ensuring your unstructured data not only complies with regulations but also actively contributes to innovation, efficiency, and superior decision-making, setting your organization up for success in a data-rich future.
Folio3 offers specialized data services tailored to help businesses unlock the full potential of their data, including comprehensive unstructured data management solutions. Our expert team assists with developing robust data strategies, implementing scalable data architectures, and deploying advanced analytics and AI capabilities.
We provide end-to-end support for building data lakes, data warehouses, and lakehouse environments, ensuring your data is clean, secure, and ready for insightful analysis. Partner with Folio3 to transform your raw data into actionable intelligence, drive innovation, and achieve your business objectives with confidence.



