

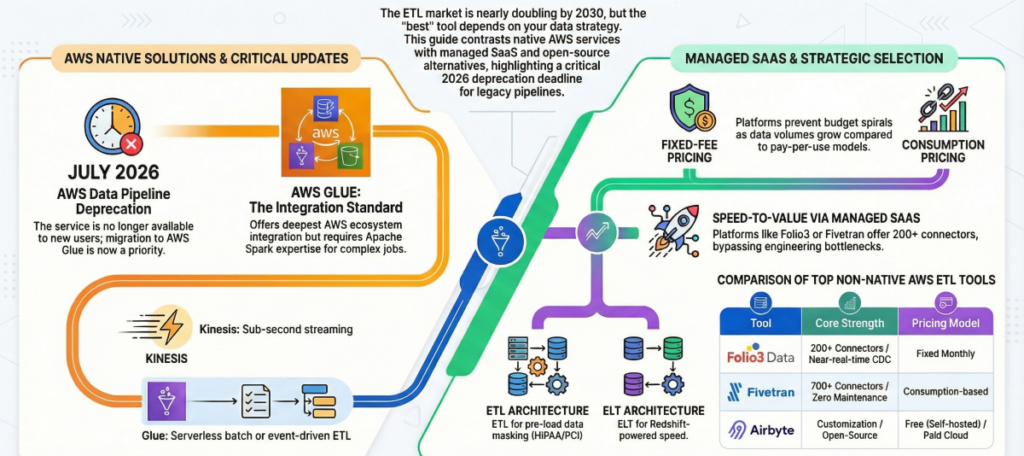
As data volumes continue to surge across cloud environments, choosing the right ETL tool for your AWS data pipelines has never been more consequential. The ETL market is projected to grow from $8.85 billion in 2025 to over $20 billion by the early 2030s, driven by accelerating cloud adoption and the growing complexity of modern data ecosystems. With AWS Data Pipeline no longer available to new users as of July 2026, organizations face a critical window to evaluate and migrate to more capable, future-proof solutions.
The good news is that the landscape of ETL options for AWS has never been richer. From AWS-native services like Glue and Kinesis to managed SaaS platforms and open-source orchestration tools, there is a solution suited to virtually every team size, budget, and technical capability. However, no single tool is the universal best choice — the right fit depends on your governance requirements, connector needs, real-time vs. batch processing demands, and whether your team has the Spark expertise to maximize native AWS tooling. This guide breaks down the leading options so you can make a confident, informed decision.
Key Takeaways
- The ETL market is projected to grow from $8.85B in 2025 to over $20B by the early 2030s, driven by accelerating cloud adoption.
- AWS Data Pipeline is no longer available to new users as of July 2026, migration planning is now critical.
- AWS Glue offers the deepest AWS ecosystem integration at $0.44/DPU-hour but requires Apache Spark expertise many teams lack.
- Fixed-fee platforms deliver budget certainty compared to consumption-based pricing that can spiral as data volumes grow.
- AWS Kinesis is purpose-built for sub-second streaming; for CDC and near-real-time batch, managed SaaS platforms are the stronger choice.
- Modern SaaS platforms enable business users to build AWS data pipelines without engineering bottlenecks, reducing dependency on scarce Spark talent.
For AWS-centric organizations, there isn’t a single “best” ETL tool; There’s a best fit for your data strategy, governance model, and team capacity. If you seek deep, secure integration with AWS services and serverless operations, AWS Glue is typically the top choice. If your priority is speed-to-value with 200+ SaaS connectors and predictable pricing, managed platforms like Folio3 Data’s offerings or Fivetran shine.
For real-time streams, Kinesis is purpose-built. And for engineering-led teams prioritizing customization and cost control, open-source options like Airbyte and orchestration with Apache Airflow offer maximum flexibility. This guide compares the leading options, cost models, and decision criteria so senior data leaders can choose an ETL approach that scales, complies, and pays back quickly.
Key criteria for choosing the best ETL tool for AWS data pipelines
ETL (extract, transform, load) moves data from sources into target systems. Tools extract from databases, APIs, and files, apply transformations for quality and structure, and load into destinations like S3 or Redshift. In AWS, the best ETL tool balances integration depth, performance, security, and total cost of ownership.
- AWS integration and governance: Seek seamless hooks into S3, Redshift, DynamoDB, IAM, and Lake Formation, plus data lineage and catalog support.
- Connector breadth and delivery speed: Broad prebuilt connectors, visual job builders, and automation reduce engineering effort and time-to-value.
- Real-time vs batch: If you need operational insights, support for CDC (change data capture) and streaming is essential; batch is sufficient for periodic analytics.
- Pricing model: Choose between serverless pay-per-use and fixed subscriptions, factoring in the variability of data volumes.
- Scale, compliance, and operations: Confirm elasticity under peak loads, certifications like SOC 2 and HIPAA, and ongoing operational overhead.
- Schema drift handling: As source systems evolve, your ETL tool must automatically detect and adapt to schema changes without breaking pipelines.
Industry momentum underscores the stakes: the ETL market is projected to grow from $8.85B in 2025 to over $20 billion by the early 2030s, reflecting surging data integration needs across cloud platforms and SaaS ecosystems.
| Criteria | Description |
| AWS Native Integration | Seamless service integration and support for IAM, KMS, Lake Formation, and governance |
| Data Connectors | Breadth of supported databases, files, and SaaS apps |
| Processing Mode | Real-time streaming and CDC vs scheduled batch |
| Pricing Model | Serverless pay-as-you-go vs fixed subscription |
| Scalability | Elasticity for surges and growth |
| Compliance | Certifications such as SOC 2, HIPAA, and GDPR |
| Schema Drift Handling | Automatic adaptation when source schemas change |
| Time-to-Value | Speed of implementation, visual tooling, automation |
ETL vs ELT for AWS data pipelines: which approach is right for you?
Before selecting a tool, understanding the difference between ETL and ELT is essential because it determines your architecture, tool shortlist, and performance profile.
ETL (Extract, Transform, Load) transforms data before it reaches your destination. Transformations happen in a dedicated processing engine, like cleaning, enriching, masking, and reshaping data before it ever touches your warehouse. This approach is ideal when data quality must be enforced early, when compliance requires pre-load masking such as HIPAA-governed patient data, or when your target warehouse has limited compute capacity.
ELT (Extract, Load, Transform) loads raw data first into a destination like Amazon Redshift, then leverages the warehouse’s own compute power to run transformations. Because modern cloud warehouses like Redshift are built for massively parallel processing, ELT can be significantly faster and more cost-efficient for large analytical workloads, and it preserves the raw data for future transformation logic changes.
- When to choose ETL: Data must be cleaned or masked before entering the warehouse, you are working with regulated data (HIPAA, PCI-DSS), or your warehouse compute is limited.
- When to choose ELT: You need speed-to-warehouse, your destination is Redshift or another high-compute warehouse, and you want to preserve raw data for iterative transformation. Most AWS-native and SaaS platforms today support ELT natively.
Why manually coding your AWS data pipeline is a hidden liability?
Before evaluating tools, it is worth understanding what you are avoiding. Some engineering teams consider building a custom AWS pipeline using raw Lambda functions, Glue scripts, and S3 event triggers. While technically feasible, the operational costs compound quickly.
A manually coded pipeline requires your engineers to learn each source API, write extraction and schema detection logic, build error handling, alerting, and retry mechanisms, and then maintain all of it as source systems change.
Schema changes upstream (a renamed column, a new field added) can silently corrupt data without robust schema drift handling. This translates directly into engineering hours that could be spent on product work, and into outages that erode stakeholder trust in data quality.
Purpose-built ETL tools absorb all of this complexity into a managed layer, delivering schema drift handling, compliance certifications, SLA-backed uptime, and visual monitoring without requiring your team to become ETL framework experts. The build vs buy calculus almost always favors purpose-built tools once you factor in ongoing maintenance, not just initial setup.
AWS native ETL tools for AWS data pipelines
Native AWS ETL tools prioritize tight service-to-service integration, built-in security with IAM, and serverless economics. They are ideal when your stack is primarily on AWS and governance is paramount. Executives should weigh the tradeoff between native integration and the connector breadth and automation often found in SaaS platforms.
| AWS Tool | Scheduling & Workflow | Scalability | Connector Support | Governance & Security | Pricing Model |
| AWS Glue | Advanced, event-driven | Serverless, auto-scale | Native AWS sources, limited SaaS | Integrated with IAM, Lake Formation | Pay-per-DPU-hour (~$0.44) |
| AWS Data Pipeline | Scheduled workflows (deprecated) | Moderate | AWS services only | IAM | Monthly pipeline charges |
| AWS Lambda | Event-triggered | Serverless, auto-scale | Custom via code | IAM, VPC support | Pay-per-request |
| AWS Glue DataBrew | Scheduled / on-demand | Serverless | AWS data stores | IAM, Lake Formation | Pay-per-session |
| AWS Kinesis | Real-time streaming | Highly scalable | Streaming data sources | IAM, encryption options | Pay-as-you-go |
AWS Glue: overview and AWS service integration
AWS Glue is a fully managed, serverless ETL service built on Apache Spark that discovers, transforms, and moves data across AWS analytics services, making it a core component of modern AWS data engineering environments. Its strengths include native integration with S3, Redshift, DynamoDB, and Athena; support for Python and Scala ETL jobs; and a visual development experience in Glue Studio with event-driven workflows that simplify productionizing serverless ETL pipelines.
| Feature | Glue Support | Limitation |
| Integration | Deep AWS service integration (S3, Redshift) | Limited external SaaS connectors |
| Development | Python/Scala support, Glue Studio visual UI | Requires Spark knowledge for complex jobs |
| Pricing | Serverless, pay-as-you-go (~$0.44/DPU-hour) | Costs can rise with heavy usage |
| Workflow Orchestration | Event-driven, schema discovery, jobs & crawlers | Cold start latency for short-lived jobs |
| Schema Management | Automated schema discovery via Glue Data Catalog | Schema drift handling requires custom code |
Pros
- Deepest AWS ecosystem integration of any ETL tool
- Fully serverless, with no infrastructure to manage
- Integrated data lineage and cataloging via Lake Formation
- Visual job authoring in Glue Studio reduces code overhead
Cons
- Requires Apache Spark expertise for complex jobs
- Limited connectors outside the AWS ecosystem
- Cold start latency on short-lived jobs
- Cost estimation is complex for variable workloads
Best for: AWS-heavy architectures requiring tight governance, data lineage, and serverless Spark-based ETL without infrastructure management.
AWS Data Pipeline vs AWS Glue for scheduling and workflows
Deprecation Notice: AWS Data Pipeline is no longer available to new users as of July 2026. If your organization currently relies on Data Pipeline, migration to AWS Glue or a managed third-party platform should be treated as an active priority, not a future consideration.
AWS Data Pipeline was a legacy AWS service for scheduling data movement and simple workflows. Glue is now the recommended path for advanced ETL, schema discovery, and serverless Spark-based transformations. For teams currently on Data Pipeline, Glue Studio provides the most natural AWS-native migration path.
| Aspect | AWS Glue | AWS Data Pipeline |
| Scheduling | Event-driven and flexible | Fixed schedule, simpler workflows |
| UI Experience | Modern, visual Glue Studio | Basic console UI |
| Operational Overhead | Serverless, fully managed | More manual configuration |
| Connector Support | AWS-native, limited SaaS | AWS services only |
| Use Case | Complex ETL, schema discovery | Data movement, batch workflows |
| Current Status | Actively supported | Deprecated — not available to new users |
| Pricing | Pay-per-DPU-hour (~$0.44) | Monthly pipeline and resource fees |
Best for: Teams still running legacy batch workflows who need a clear migration path, move to AWS Glue for AWS-native workloads or a managed SaaS platform for broader connectivity.
AWS Lambda for event-driven ETL
AWS Lambda is a serverless computing service that executes code in response to events such as S3 object uploads, DynamoDB table updates, API Gateway requests, or custom triggers. While not a dedicated ETL platform, Lambda is widely used to build lightweight, custom transformation functions within larger AWS data pipelines, including workflows that connect AWS IoT Analytics with downstream processing layers.
Lambda supports Python, Node.js, Java, Ruby, Go, and PowerShell, giving engineering teams flexibility to write custom extraction and transformation logic. It responds in milliseconds to events and integrates natively with S3, DynamoDB, Kinesis, and RDS, making it a strong orchestration layer between AWS services.
Pros
- Millisecond response to events, ideal for lightweight transformations
- Native integration across the entire AWS service ecosystem
- Pay only when code executes, with no idle compute cost
- Supports all major programming languages
Cons
- Not suited for large-scale batch ETL or complex multi-step transformations
- 15-minute execution limit restricts heavy processing jobs
- Requires custom development for every pipeline, with no prebuilt connectors
- Operational complexity grows with pipeline size
Best for: Small, event-triggered transformations within AWS (for example, processing new S3 files on arrival) as a lightweight component inside a larger pipeline, not as a standalone ETL solution.
AWS Glue DataBrew for no-code data preparation
AWS Glue DataBrew is a visual data preparation tool that simplifies cleaning and normalizing data before it enters analytics or machine learning workflows. Unlike Glue’s developer-oriented Spark environment, DataBrew is designed for data analysts and business users who do not have deep coding expertise.
Users can pull data from AWS data stores, apply over 250 built-in transformations; handling missing values, normalizing formats, detecting outliers, and removing duplicates, and then automate those steps as reusable recipes. DataBrew integrates directly with S3, Redshift, Glue Data Catalog, and Lake Formation, making it a natural fit for organizations already standardized on the AWS analytics stack.
Pros
- Visual, no-code interface accessible to analysts without Spark skills
- 250+ built-in transformations covering most data preparation scenarios
- Deep integration with Glue Data Catalog and Lake Formation
- Reusable transformation recipes reduce repetitive work
Cons
- Not a full ETL platform, focused on data prep, not pipeline orchestration
- Limited connector support beyond AWS data sources
- Session-based pricing can accumulate costs on frequent jobs
- Better suited as a preprocessing step than a standalone pipeline tool
Best for: Data analysts and business teams needing visual data preparation within the AWS ecosystem before analytics or ML, without requiring Spark expertise.
AWS Kinesis for real-time data processing
AWS Kinesis provides native real-time data ingestion and analytics through Data Streams, Firehose, and Analytics, enabling sub-minute pipelines for clickstreams, IoT telemetry, and log analytics. Unlike Glue or Data Pipeline, Kinesis is built for streaming workloads with low-latency delivery rather than batch ETL, and it commonly feeds S3, Redshift, or Lambda for downstream processing.
Pros
- Purpose-built for real-time streaming, sub-second latency achievable
- SQL streaming capabilities via Kinesis Data Analytics
- Auto-scales for variable workloads and traffic spikes
- Deep integration with Lambda for event-driven architectures
Cons
- Not suited for traditional batch ETL workloads
- Requires streaming architecture expertise
- Complex pricing across multiple Kinesis service tiers
Best for: IoT, log analytics, clickstreams, and event-driven architectures requiring real-time or near-real-time data processing on AWS.
Managed SaaS ETL tools for AWS pipelines
SaaS ETL platforms emphasize broad connectors, low-code design, and fast onboarding, often with enterprise compliance baked in. They compress time-to-value and reduce engineering burden, making them a practical alternative to fully custom data engineering and ETL/ELT services. However, recurring subscription or consumption fees can outpace serverless costs at very large scale.
| Tool | Connectors | Pricing Model | Compliance | Time-to-Value |
| Folio3 Data | 200+ including AWS sources | Fixed monthly | SOC 2, HIPAA, GDPR | Rapid, low-code UI |
| Fivetran | 700+ prebuilt library | Consumption-based (MAR) | SOC 2 | Automated setup |
| Matillion | Cloud warehouse-native | Subscription | SOC 2 | Optimized for Redshift |
| Stitch | 140+ sources | Subscription | SOC 2, HIPAA, GDPR | Simple ingestion |
| Hevo Data | 150+ sources | Event-based tiers | SOC 2 | No-code, rapid setup |
1. Folio3 Data for low-code ETL with fixed pricing
Folio3 Data combines ETL, ELT, CDC, and Reverse ETL in one data integration platform and offers a low-code, drag-and-drop UI with 220+ transformations and 200+ prebuilt connectors spanning Redshift, S3, and RDS. The platform is compliance-ready (SOC 2, GDPR, HIPAA, CCPA) and features a fixed monthly plan with sub-60-second CDC for near-real-time sync.
CDC (change data capture) tracks and applies row-level changes in near real time from source systems to targets, making it essential for operational analytics and real-time reporting on AWS.
Pros
- Fixed-fee pricing eliminates consumption-based cost unpredictability
- Sub-60-second CDC for near-real-time data sync to Redshift and S3
- 200+ prebuilt connectors including native AWS RDS, S3, and Redshift integrations
- SOC 2, GDPR, HIPAA, and CCPA compliance out of the box
- Low-code interface empowers both technical and non-technical users
Cons
- Fixed pricing may not be cost-optimal for very low data volumes
- Newer platform with less market history than legacy enterprise tools
Best for: Organizations that need predictable monthly costs, near-real-time CDC, and broad SaaS connectivity without sacrificing compliance or AWS integration depth.
2. Fivetran for automated ELT and rich connectors
Fivetran is a fully automated ELT platform known for its robust connector ecosystem with 700+ managed connectors, automated schema drift handling, and incremental sync. It is built for analytics teams that want reliable, zero-maintenance pipelines.
Pros
- Fully managed, zero-maintenance pipelines
- 700+ connectors covering SaaS, databases, and event sources
- Automatic schema drift handling adapts to source changes
- Embedded dbt Core for transformation workflows
Cons
- Consumption-based MAR pricing can become unpredictable at scale
- ELT-only, with no transform-before-load option
- Premium pricing may be challenging for budget-constrained teams
Best for: Enterprises that prioritize reliability, low operational overhead, and fully managed automation, and have the budget to support consumption-based pricing.
3. Matillion for cloud data warehouse-native transformations
Matillion executes transformations where the data lives, inside Redshift, Snowflake, or BigQuery, to reduce latency and maximize performance. It supports dbt, CI/CD-friendly workflows, and fine-grained development lifecycle controls, making it a strong fit for BI and analytics teams standardizing on Redshift or Snowflake.
Pros
- Push-down ELT maximizes warehouse compute efficiency
- Strong dbt integration for modern transformation workflows
- Visual low-code interface with SQL support for technical users
- Strong orchestration and visualization capabilities
Cons
- Focused primarily on warehouse transformation, not broad ETL across all sources
- Higher learning curve than pure no-code platforms
- Credit-based pricing requires ongoing monitoring
Best for: Organizations building modern cloud data warehouses on Redshift or Snowflake that want warehouse-native performance and transformation depth.
4. Stitch for lightweight ingestion and simple pricing
Stitch focuses on straightforward ELT into Redshift or S3, with 140+ sources and a no-frills SaaS model. It offers SOC 2, HIPAA, and GDPR compliance and transparent subscription pricing, ideal for small to mid-scale teams that want dependable ingestion without complex transformation layers.
Pros
- Lowest entry price among paid ETL platforms
- Quick deployment for standard integrations
- SOC 2, HIPAA, and GDPR compliance
- Simple row-based pricing tiers are easy to forecast
Cons
- Limited transformation capabilities — better for ingestion than complex ETL
- Fewer connectors than enterprise-grade alternatives
- Basic feature set may require supplementary tools as needs grow
Best for: Small businesses and marketing teams needing budget-friendly, straightforward data centralization into Redshift or S3 without complex transformation requirements.
5. Hevo Data for no-code pipeline simplicity
Hevo Data delivers true no-code simplicity with 150+ prebuilt connectors and automatic schema detection. The platform provides real-time data sync with native AWS support for S3, RDS, and Redshift, making it accessible to teams without dedicated data engineering resources.
Pros
- Intuitive no-code interface — non-engineers can build and manage pipelines
- Real-time data loading with minimal latency
- Automatic schema detection and mapping reduces manual work
- Native integrations for AWS S3, RDS, and Redshift
Cons
- Fewer connectors than enterprise platforms
- Limited advanced transformation capabilities for complex processing
- Smaller market presence compared to more established tools
Best for: Teams without dedicated data engineering resources that need straightforward, no-code data integration with real-time sync into AWS.
Open-source and orchestration-focused ETL tools
Open-source ETL and workflow engines offer extensibility, cost control, and deep customization, best for engineering-first teams ready to invest in operations and maintenance. They shine when you need custom connectors, nonstandard logic, or to avoid vendor lock-in.
| Tool | Extensibility | Required Expertise | Total Cost of Ownership |
| Airbyte | High, custom connectors | Engineering team needed | Low software cost, higher ops overhead |
| Apache Airflow | Very high, DAG workflows | Advanced Python skills | Free software, significant maintenance |
| Managed SaaS | Limited | Low | Higher subscription costs |
1. Airbyte for customizable connectors and open-source flexibility
Airbyte is an open-source ELT platform supporting self-hosting and custom connector development, with an optional managed cloud offering for automated scaling. Teams can start free and move to paid cloud tiers for higher volumes, making it attractive when specialized sources outstrip commercial connector coverage.
Pros
- Open-source foundation with active community development
- No-code connector builder for custom integrations
- SOC 2, ISO, GDPR, HIPAA compliance certifications
- Self-hosted or cloud deployment flexibility
Cons
- Self-hosted deployment requires technical expertise and infrastructure management
- Community connectors vary in quality and maintenance
- More operational overhead than fully managed platforms
Best for: Engineering teams that need custom connector builds, maximum control over deployments, and want to avoid vendor lock-in.
2. Apache Airflow for complex orchestration and workflow control
Apache Airflow is a Python-based workflow engine that models pipelines as DAGs (Directed Acyclic Graphs), enabling granular orchestration, complex dependencies, and integration across AWS and on-premises systems. It is often used to coordinate AWS real-time data pipelines where multiple streaming, batch, and transformation stages must run in a specific order. The tradeoff is operational complexity, as it requires significant setup and ongoing management, but it offers unmatched flexibility for sophisticated data platforms.
Pros
- Unmatched flexibility for complex, multi-step pipeline orchestration
- DAG-based workflows handle intricate dependency chains
- Large community and deep AWS integration options
- Fully customizable logic, with no platform constraints
Cons
- Significant setup and infrastructure management required
- Requires advanced Python skills for effective use
- No native connectors, with all integrations require engineering effort
Best for: Engineering-led teams building sophisticated, multi-system data platforms where custom orchestration logic and maximum control outweigh the cost of operational complexity.
Comparison of pricing models and cost implications
Pricing shapes not just monthly spend but your operating model. Serverless pay-per-use offers elasticity with variable costs; consumption pricing aligns to data volume but can spike; fixed-fee subscriptions simplify budgeting. Always include people and platform overhead in total cost of ownership.
| Tool | Pricing Model | Cost Drivers | Notes |
| Folio3 Data | Fixed monthly | Flat fee | Predictable budgeting |
| AWS Glue | Serverless, pay-per-DPU-hour | DPU-hours per job | Elastic scaling, variable monthly cost |
| Fivetran | Consumption-based (MAR) | Data volume, connectors, sync frequency | Variable cost, minimal ops overhead |
| Airbyte | Free / self-hosted + cloud tiers | Events processed, compute | Free tier; paid cloud tiers available |
| Stitch | Subscription | Sources, row volume | Simple pricing, good for smaller loads |
| Matillion | Subscription | Users, data volume, environment | Warehouse-native performance |
| Informatica | Custom enterprise | IPU-based, deployment size | Highest TCO, full enterprise governance |
Serverless consumption pricing versus fixed-fee subscription
Glue’s serverless pricing (~$0.44 per DPU-hour) is ideal when workloads fluctuate or you want to tightly match spend to usage. Fixed-fee subscriptions offer simplicity and predictable budgeting at the expense of pure elasticity. Open-source options provide a middle ground between control and convenience but require engineering investment to operate.
Cost predictability and operational overhead considerations
Fixed-fee SaaS improves budget forecasting and reduces staffing needs, but can create lock-in and higher lifetime spend at very large scale. Serverless and open-source models can lower platform costs yet demand stronger engineering, observability, and capacity planning. Align pricing style to team expertise, workload variability, compliance demands, and time-to-insight goals.
Practical guidance for choosing the right ETL tool for your AWS environment
A pragmatic selection flow:
Is your stack primarily AWS with strong governance needs? Start with AWS Glue. For visual authoring, Glue Studio reduces the Spark skill barrier considerably.
Do you need 200+ SaaS connectors, low-code delivery, and fast time-to-value? Choose a managed SaaS platform. Folio3 Data for fixed pricing and CDC; Fivetran for automated ELT at scale.
Do you need no-code simplicity with minimal engineering resources? Look at Hevo Data or Glue DataBrew depending on whether you need a full pipeline tool or data prep capability.
Do you require enterprise governance, MDM, and hybrid infrastructure support? Evaluate Talend or Informatica depending on scale and budget.
Do you require custom connectors or advanced orchestration? Combine Airbyte (ELT) with Apache Airflow (workflow) for maximum control and to avoid lock-in.
Reconcile pricing with strategy: serverless for elasticity, consumption for simplicity with variability, fixed-fee for predictability. Tie the decision to compliance, TCO, and speed-to-insight.
When to choose AWS Glue for deep AWS integration and governance
Select Glue when you run an AWS-heavy architecture and need tight integration with Lake Formation, Redshift, and the Data Catalog, especially for Spark-based ETL in a serverless model. Budget for Python/Scala/Spark skills, consider Glue Studio to accelerate build-out, and watch DPU usage and potential cold starts on short jobs.
Selecting managed SaaS tools for rapid deployment and predictable costs
Choose SaaS ETL when you prioritize the fastest time-to-value, prebuilt connectors, and compliance assurances. Folio3 Data excels with fixed pricing and near-real-time CDC, while Fivetran fits high-scale analytics pipelines with minimal ops. Monitor growth carefully to avoid unforeseen costs with consumption models.
Leveraging open-source and orchestration tools for customization and control
Adopt Airbyte or Airflow when you need nonstandard connectors, code-first logic, or to avoid platform lock-in. Expect to invest in engineering, DevOps, and monitoring — but gain fine-grained control over performance, cost, and roadmap.
Frequently asked questions
Is AWS Data Pipeline still available?
AWS Data Pipeline is no longer available to new users as of July 2026. Organizations still running workloads on Data Pipeline should prioritize migration to AWS Glue or a managed third-party ETL platform as soon as possible.
Should I use AWS Glue or a managed SaaS platform?
AWS Glue is best when your stack is deeply AWS-native and you have Spark expertise. Managed SaaS platforms are the better choice when you need faster time-to-value, 200+ SaaS connectors, or predictable fixed-fee pricing without requiring Spark skills.
What is the difference between ETL and ELT for AWS?
ETL transforms data before loading into your destination warehouse, which is ideal for compliance-sensitive use cases. ELT loads raw data first and transforms it using warehouse compute like Redshift — better for speed and flexibility at scale. Most modern platforms support both patterns.
Which ETL tool handles real-time data processing most effectively?
AWS Kinesis is purpose-built for real-time streaming on AWS. For near-real-time CDC (change data capture), managed SaaS platforms with sub-60-second CDC capabilities are strong alternatives that also handle batch workloads in the same platform.
What is CDC and why does it matter for AWS pipelines?
Change data capture (CDC) tracks row-level changes in source databases and applies them to target systems in near real time. It is essential for operational analytics use cases where you need your Redshift data warehouse to reflect live source system changes within seconds, not hours.
Conclusion
Choosing the best ETL tool for AWS ultimately comes down to how well the platform aligns with your architecture, governance needs, team expertise, and cost model. While AWS-native services like Glue offer deep ecosystem integration, managed SaaS platforms and open-source tools each present distinct advantages across speed, flexibility, and operational overhead depending on your pipeline requirements.
Folio3 Data Services accelerates this process by delivering end-to-end AWS IoT Analytics solutions from device onboarding and pipeline orchestration to lakehouse integration and ML-ready datasets, helping enterprises gain fast, governed insights from every connected device.



