

Generative AI has moved beyond experimental use cases to become a strategic imperative for enterprise organizations seeking competitive advantages through intelligent automation, enhanced customer experiences, and operational efficiency gains. Companies like Microsoft report 70% productivity improvements in software development, while financial services firms achieve 40% faster document processing through generative AI implementations.
However, success in generative AI depends fundamentally on data strategy rather than just model selection or technology deployment. The quality, structure, and accessibility of enterprise data determine whether AI initiatives deliver transformational business value or become expensive technical experiments that fail to meet expectations.
Traditional data strategies designed for business intelligence and analytics don’t adequately support generative AI requirements. Large language models need massive amounts of high-quality, contextually rich data that can be processed in real-time while maintaining governance standards and regulatory compliance.
This blog examines how organizations can develop data strategies specifically designed for generative AI success, covering architecture requirements, governance frameworks, implementation approaches, and practical applications that create measurable business value.
What Is a Data Strategy for Generative AI?
A data strategy for generative AI encompasses the policies, architecture, processes, and governance frameworks that enable organizations to collect, prepare, and deliver data optimized for training, fine-tuning, and operating large language models and other generative AI systems.
Unlike traditional data strategies focused on structured analytics and reporting, generative AI data strategies must handle diverse data modalities including text, images, audio, and code while maintaining context and semantic relationships that enable intelligent responses and content generation.
The strategy addresses both technical requirements like vector databases and embedding models alongside business considerations including responsible AI practices, regulatory compliance, and operational sustainability that support long-term generative AI success. Modern generative AI data strategies also incorporate real-time data processing capabilities that enable adaptive learning, personalization, and dynamic response generation that keeps pace with changing business conditions and user needs.
Why Does Generative AI Demand a New Data Strategy?
Generative AI introduces unique data requirements that traditional enterprise data architectures and processes weren’t designed to handle effectively. Developing a modern enterprise data strategy becomes essential, as organizations must account for new types of data, governance models, and integration patterns that go beyond conventional analytics approaches.
Structured vs. Unstructured Needs
Traditional enterprise analytics focus primarily on structured data from databases and operational systems, while generative AI requires extensive unstructured data including documents, emails, chat transcripts, images, and multimedia content that contains the contextual information needed for intelligent responses.
Processing unstructured data at the scale required for enterprise generative AI demands specialized storage architectures, preprocessing pipelines, and quality management processes that differ significantly from conventional data warehouse approaches.
The integration of structured and unstructured data creates additional complexity as generative AI systems need to understand relationships between quantitative metrics and qualitative context to provide accurate and relevant outputs.
Metadata & Context Importance
Generative AI models require rich metadata and contextual information to understand data relationships, source credibility, and content relevance that enable accurate and appropriate response generation.
Context preservation becomes critical when dealing with enterprise knowledge that spans multiple departments, time periods, and business functions. Without proper context, generative AI systems may provide technically accurate but business-inappropriate responses.
Metadata management for generative AI must capture semantic relationships, data lineage, quality indicators, and business context that traditional metadata systems often overlook or treat as secondary considerations.
Data Quality and Relevance for LLMs
Large language models are particularly sensitive to data quality issues, with poor-quality training data leading to hallucinations, biased responses, and unreliable outputs that can damage business operations and customer relationships.
Data relevance becomes more complex for generative AI because models need to understand not just what information is accurate, but when and how that information should be applied to specific business contexts and user queries.
Quality assessment for generative AI data requires new metrics that evaluate semantic consistency, factual accuracy, and contextual appropriateness rather than just completeness and format compliance used in traditional data quality programs.
A carefully structured data strategy roadmap helps enterprises align governance, pipeline design, and quality controls with AI adoption goals, ensuring data remains trustworthy and fit for purpose as systems evolve.
Examples: Prompt Tuning, Fine-Tuning, Retrieval-Augmented Generation (RAG)
Prompt tuning requires carefully curated examples and context that demonstrate desired response patterns, demanding high-quality training data that represents the full range of business scenarios the AI system will encounter.
Fine-tuning processes need domain-specific datasets that maintain consistent quality, format, and business relevance while providing sufficient volume and diversity to train effective specialized models.
RAG implementations depend on comprehensive knowledge bases with accurate embeddings and semantic indexing that enable precise information retrieval and contextually appropriate response generation.
What Are the Core Pillars of a Generative AI Data Strategy?
Successful generative AI data strategies build on four fundamental pillars that address the unique requirements of AI-powered business applications.
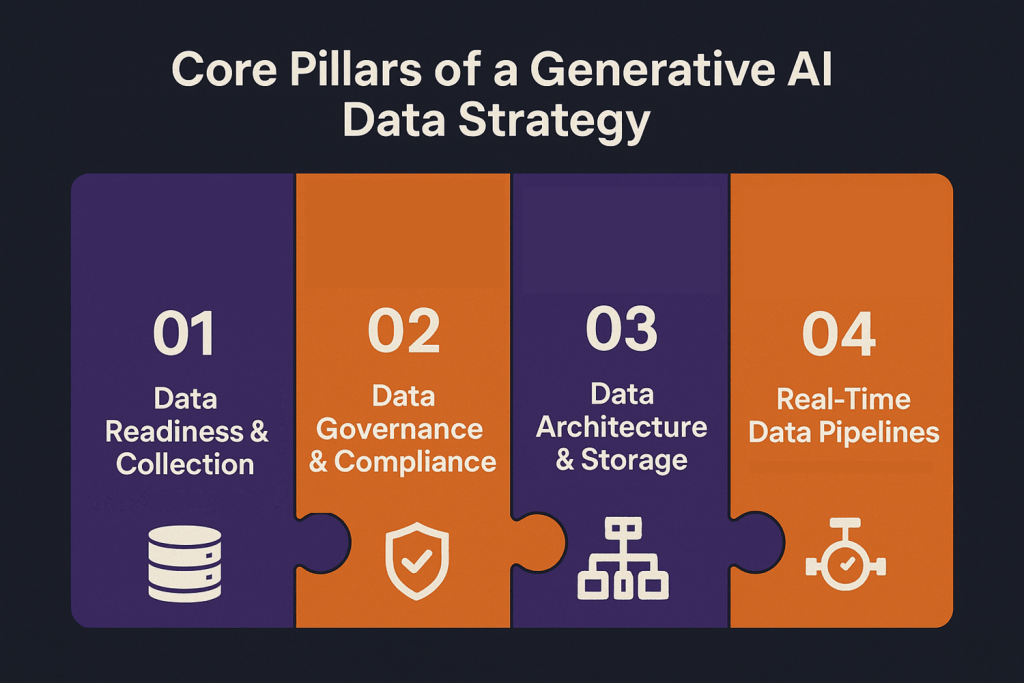
1. Data Readiness & Collection
Data readiness for generative AI requires comprehensive collection strategies that capture diverse data modalities while maintaining quality and context standards necessary for effective model training and operation.
Text, Image, Audio, Code — Modality-Specific Considerations
Text data collection must preserve formatting, metadata, and contextual relationships that enable semantic understanding, while ensuring content quality and relevance to business objectives and user needs.
Image data requires consistent resolution standards, accurate labeling, and metadata preservation that supports visual understanding tasks like document analysis, product recognition, and visual content generation.
Audio data processing demands specialized pipelines for transcription, speaker identification, and context preservation that enable voice-based AI applications and multimedia content analysis.
Code repositories need careful curation to maintain syntax accuracy, documentation completeness, and version control information that supports intelligent code generation and analysis capabilities.
First-Party Data vs Third-Party Sources
First-party enterprise data provides the most relevant and controllable foundation for generative AI applications, offering unique competitive advantages through proprietary knowledge and customer insights.
Building a robust customer data strategy around first-party information ensures organizations can maximize personalization, trust, and long-term business value from their AI initiatives.
Third-party data sources can supplement first-party information but require careful evaluation for quality, bias, licensing terms, and alignment with business objectives and ethical standards.
Data source mixing strategies must account for potential conflicts, quality differences, and integration challenges that could impact model performance and business outcomes.
2. Data Governance & Compliance
Strong data governance strategy frameworks for generative AI must address responsible AI practices, regulatory compliance, and risk management while enabling innovation and business value creation.
Responsible AI, Bias Mitigation, Explainability
Bias detection and mitigation require continuous monitoring of training data and model outputs to identify and address discriminatory patterns that could harm business relationships or violate ethical standards.
Explainability frameworks enable organizations to understand how generative AI systems make decisions, supporting debugging, improvement efforts, and regulatory compliance requirements.
Responsible AI practices include content filtering, output monitoring, and human oversight processes that prevent inappropriate or harmful content generation while maintaining system effectiveness.
Regulatory Concerns (GDPR, HIPAA, etc.)
GDPR compliance requires careful data handling, consent management, and right-to-be-forgotten capabilities that may conflict with traditional model training approaches requiring data persistence.
HIPAA regulations in healthcare demand specialized security measures, access controls, and audit trails for medical data used in generative AI applications.
Industry-specific regulations create additional complexity requiring legal review and technical implementation of compliance measures that vary by jurisdiction and business sector.
3. Data Architecture & Storage
AI-ready architecture must support diverse data types, real-time processing, and scalable storage while maintaining performance standards necessary for production generative AI applications.
Vector Databases, Data Lakes, Hybrid Architectures
Vector databases enable semantic search and similarity matching essential for RAG implementations and intelligent content retrieval, requiring specialized indexing and query optimization approaches.
Data lakes provide flexible storage for diverse data modalities while supporting the scale requirements of generative AI training and inference operations.
Hybrid architectures combine traditional data warehouses with modern AI-optimized storage systems, enabling organizations to use existing investments while adding generative AI capabilities.
4. Real-Time Data Pipelines
Streaming data pipeline processing enables adaptive learning, personalization, and dynamic response generation that keeps generative AI systems current with changing business conditions and user preferences.
Streaming for Adaptive Learning Models
Real-time data ingestion supports continuous learning approaches that improve model performance based on user feedback, business outcomes, and changing data patterns.
Streaming architectures must handle high-volume, low-latency data processing while maintaining quality standards and enabling immediate integration with generative AI systems.
Feedback loop implementation creates closed-loop systems where model outputs inform data collection and processing strategies, improving performance over time.
How Can Organizations Build a Data Strategy for Generative AI?
A systematic approach to data strategy development ensures alignment with business objectives while addressing technical requirements and risk management considerations.
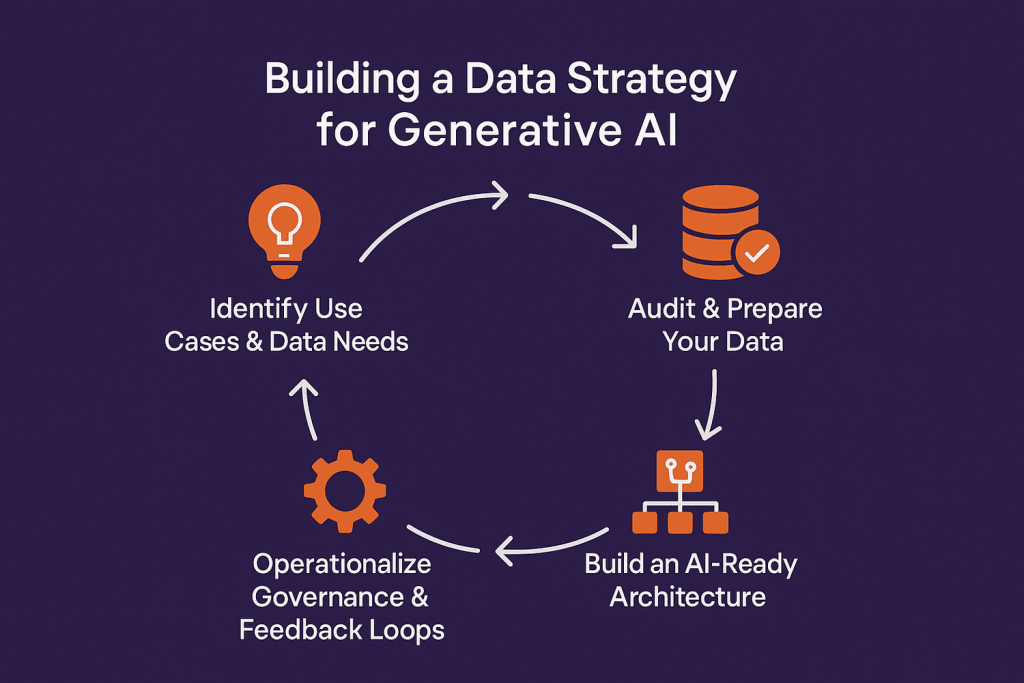
Step 1: Identify Use Cases & Data Needs
Use case identification should focus on specific business problems where generative AI can create measurable value, such as customer support automation, content creation, or document analysis.
Data needs assessment examines existing data assets to identify gaps, quality issues, and infrastructure requirements necessary to support identified use cases effectively.
A structured data strategy assessment at this stage helps organizations evaluate whether their current capabilities, governance policies, and technology stack are sufficient to support generative AI adoption or if significant adjustments are required.
Business impact analysis helps prioritize use cases based on potential value creation, implementation complexity, and strategic alignment with organizational objectives.
Step 2: Audit & Prepare Your Data
Comprehensive data auditing evaluates quality, completeness, bias, and suitability for generative AI applications while identifying improvement opportunities and compliance risks.
Many organizations also leverage specialized data strategy services at this stage to accelerate the auditing and preparation process, ensuring data pipelines meet both compliance and AI-readiness requirements.
Data preparation processes include cleaning, formatting, annotation, and enrichment activities that transform raw enterprise data into AI-ready assets.
Quality improvement initiatives address identified issues through automated processing, manual curation, and ongoing monitoring processes that maintain data standards over time.
Step 3: Build an AI-Ready Architecture
Architecture design must balance performance, scalability, and cost efficiency while supporting diverse generative AI workloads and integration with existing enterprise systems.
Designing the right data integration architecture helps unify structured, unstructured, and streaming sources so they can feed into AI pipelines consistently and without creating silos.
Technology selection should consider factors including data volume, processing requirements, security needs, and integration complexity when choosing storage, processing, and management platforms.
Infrastructure implementation requires careful planning for compute resources, network capacity, and security measures that support production generative AI applications.
Step 4: Operationalize Governance & Feedback Loops
Governance implementation creates policies, procedures, and monitoring systems that ensure responsible AI practices while enabling innovation and business value creation.
Feedback loop design establishes processes for collecting user input, monitoring model performance, and implementing improvements based on business outcomes and user satisfaction.
Continuous improvement frameworks enable organizations to refine their data strategies based on experience, changing requirements, and evolving technology capabilities.
Step 5: Measure, Optimize, and Scale
Performance measurement should track both technical metrics like model accuracy and business outcomes including user satisfaction, productivity improvements, and cost reductions.
Optimization efforts focus on improving data quality, model performance, and operational efficiency while maintaining governance standards and business alignment.
Scaling strategies address growing data volumes, expanding use cases, and organizational adoption while preserving system performance and maintaining quality standards.
What Tools & Technologies Support GenAI Data Strategy?
Modern technology platforms provide the infrastructure and capabilities necessary for implementing comprehensive generative AI data strategies at enterprise scale. Here are some of the tools and technologies that support GenAI strategy:
LLMOps and Data Pipeline Platforms
LLMOps platforms integrate model training, deployment, and monitoring with data pipeline management, enabling end-to-end generative AI workflow automation and governance.
Apache Airflow, Kubeflow, and MLflow provide orchestration capabilities that manage complex data processing and model training workflows while maintaining versioning and audit trails.
Cloud-native platforms like Amazon SageMaker, Google Vertex AI, and Azure Machine Learning offer integrated environments that combine data processing, model development, and deployment capabilities.
Metadata Management Tools
Apache Atlas, DataHub, and Collibra provide metadata management capabilities that track data lineage, quality metrics, and business context essential for generative AI applications.
Automated metadata discovery tools analyze data sources to extract schema information, relationships, and quality indicators that inform AI model development and deployment decisions.
Business glossary integration ensures that AI systems understand enterprise terminology and context, improving response accuracy and business relevance.
Embedding Models and Vector DBs (e.g., Pinecone, Weaviate, FAISS)
Vector databases like Pinecone, Weaviate, and Chroma provide semantic search capabilities essential for RAG implementations and intelligent content retrieval.
FAISS and similar libraries enable efficient similarity search across large datasets, supporting real-time query processing and personalization capabilities.
Embedding model integration transforms text, images, and other data types into vector representations that enable semantic understanding and intelligent matching.
Organizations often work with data integration consultants to design and connect these systems with enterprise data sources, ensuring smooth interoperability and scalability across AI pipelines.
What Key Challenges Must Organizations Address?
Understanding common implementation challenges helps organizations prepare appropriate strategies and allocate resources effectively for generative AI data strategy success.
Poor Data Quality and Fragmentation
Data quality issues including inconsistent formats, missing information, and outdated content can severely impact generative AI performance and business outcomes.
Fragmented data across multiple systems creates integration challenges that must be addressed through comprehensive data architecture and processing strategies.
Legacy system limitations may prevent real-time data access or require expensive modernization projects to enable effective generative AI implementation.
Lack of Metadata and Contextual Signals
Insufficient metadata limits AI systems’ ability to understand data relationships, source credibility, and appropriate usage contexts for different business scenarios.
Missing contextual information can lead to inappropriate AI responses that are technically accurate but business-irrelevant or potentially harmful to customer relationships.
Semantic understanding gaps occur when AI systems lack the business context necessary to interpret data correctly within specific organizational or industry frameworks.
Addressing these gaps often requires layering metadata with predictive analytics techniques that enhance context awareness and improve the quality of AI-driven insights.
Governance and Privacy Risks
Regulatory compliance requirements create complex constraints on data usage, model training, and output monitoring that must be balanced against innovation and business value goals.
Privacy protection requires a robust data protection strategy with specialized measures like anonymization, access controls, and audit trails that can impact system performance and complexity.
Ethical AI considerations require ongoing monitoring and intervention capabilities to prevent biased or harmful outputs while maintaining system effectiveness and user satisfaction.
Infrastructure Complexity
Scalable architecture design must handle diverse data types, real-time processing, and variable workloads while maintaining performance standards and cost efficiency.
Integration challenges arise when connecting generative AI systems with existing enterprise applications, databases, and workflow management systems.
In many cases, AI data extraction plays a key role in simplifying these integrations by converting unstructured inputs into structured formats that downstream systems can process more efficiently.
Resource management becomes complex when balancing compute requirements for model training, inference, and data processing across multiple workloads and business priorities.
Model Drift and Feedback Loop Gaps
Model performance degradation over time requires continuous monitoring and retraining processes that depend on fresh, high-quality data and robust feedback mechanisms.
Feedback collection challenges limit organizations’ ability to improve AI systems based on user satisfaction, business outcomes, and changing requirements.
Adaptation delays occur when data processing and model update cycles can’t keep pace with changing business conditions or user expectations.
What Are Practical Applications of Data Strategy in Generative AI?
Real-world implementations demonstrate how comprehensive data strategies enable successful generative AI applications across different business functions and industries.
Customer Support with RAG
Intelligent customer support systems combine RAG architectures with customer service analytics to deliver accurate, contextual responses by retrieving relevant information from enterprise knowledge bases and combining it with large language model capabilities.
Data strategy requirements include comprehensive documentation repositories, conversation history analysis, and real-time feedback integration that improves response quality over time.
Success metrics include first-call resolution rates, customer satisfaction scores, and agent productivity improvements that demonstrate business value from AI-powered support capabilities.
Brand-Specific Content Generation
Marketing teams use generative AI to create brand-consistent content by training models on approved messaging, style guides, and successful campaign examples that maintain brand voice and quality standards.
Data curation processes ensure training materials reflect current brand positioning, target audience preferences, and regulatory requirements across different markets and channels.
Content approval workflows integrate human oversight with AI generation to maintain quality control while achieving scale and efficiency benefits from automated content creation.
Legal Document Summarization
Legal departments use generative AI to analyze contracts, regulations, and case law by processing structured legal databases alongside unstructured document repositories.
Integrating AI enterprise search allows legal teams to instantly locate relevant clauses, precedents, or compliance documents across large repositories, significantly reducing research time and improving accuracy.
Specialized data processing handles legal formatting, citation management, and regulatory context that enables accurate analysis and summarization of complex legal documents.
Compliance monitoring ensures AI-generated legal content meets professional standards and regulatory requirements while providing efficiency benefits for routine document review tasks.
Internal Knowledge Assistants
Enterprise knowledge management systems use generative AI to help employees access institutional knowledge, policies, and procedures through conversational interfaces that understand business context.
Data strategy encompasses employee handbooks, process documentation, training materials, and tribal knowledge capture that creates comprehensive organizational intelligence resources.
Organizations increasingly pair these assistants with data analytics services and solutions to ensure responses are both contextually accurate and grounded in the latest business intelligence, further strengthening decision-making and employee productivity.
FAQs
Why is data strategy important for Generative AI?
Data strategy determines generative AI success because model quality depends entirely on training data relevance, accuracy, and context. Poor data strategy leads to unreliable outputs, biased responses, and failed business applications despite significant technology investments.
What kind of data is best for generative AI?
High-quality, contextually rich data that includes diverse formats (text, images, audio), comprehensive metadata, and business context performs best. First-party enterprise data provides competitive advantages through unique knowledge and customer insights.
Can I use existing enterprise data for LLMs?
Existing data can be valuable but typically requires significant preparation including quality improvement, format standardization, and context enrichment. Most enterprises need specialized data processing pipelines to make legacy data suitable for generative AI.
What role does data governance play in a GenAI strategy?
Data governance ensures responsible AI practices, regulatory compliance, and risk management while enabling innovation. It addresses bias mitigation, privacy protection, content filtering, and audit requirements essential for enterprise AI deployment.
Do I need a vector database for generative AI?
Vector databases are essential for RAG implementations and semantic search capabilities that enable intelligent information retrieval. While not required for all generative AI use cases, they significantly improve performance for knowledge-based applications.
Can synthetic data be used in a Generative AI data strategy?
Synthetic data can supplement real data for training and testing, particularly when privacy concerns limit real data usage. However, synthetic data should complement rather than replace authentic enterprise data that provides unique business context.
What are the biggest challenges in creating a GenAI data strategy?
Primary challenges include data quality improvement, infrastructure complexity, governance implementation, and integration with existing systems. Organizations also struggle with skills gaps and change management required for successful adoption.
How do I measure the success of my Generative AI data strategy?
Success metrics should include both technical measures (model accuracy, system performance) and business outcomes (productivity improvements, cost reductions, user satisfaction). Regular assessment helps identify optimization opportunities and demonstrate ROI.
Conclusion
As generative AI capabilities continue advancing rapidly, the organizations with robust data strategies will be positioned to capitalize on new opportunities while those with inadequate data foundations will struggle to achieve meaningful business value from their AI investments. The time to build these capabilities is now, before competitive pressures make differentiation more challenging.For organizations seeking expert guidance in developing comprehensive data strategies for generative AI success, Folio3 Data Services provides specialized consulting and implementation support that accelerates time-to-value while ensuring scalable, governance-compliant solutions. Their experience across diverse industries and AI technologies enables strategic data architecture decisions that drive measurable business outcomes.



