

Organizations today generate data at unprecedented rates, yet many struggle to extract meaningful insights from their growing information assets. Traditional data warehouses, while reliable for structured reporting, can’t handle the variety and velocity of modern data sources—from IoT sensors and social media feeds to machine learning model outputs and real-time transaction streams.
A data lake is a centralized repository that stores vast amounts of raw data in its native format, allowing organizations to capture everything first and determine its use later. Unlike traditional data warehouses that require predefined schemas and extensive ETL processes, data lakes accept structured, semi-structured, and unstructured data from any source without upfront transformation requirements.
Data lakes have become critical components of modern data architecture because they enable advanced analytics, machine learning initiatives, and real-time decision-making at scale. Companies like Netflix use data lakes to power recommendation engines that drive 80% of viewer engagement, while financial institutions leverage them for fraud detection systems that analyze millions of transactions in real-time.
This blog provides a comprehensive roadmap for successful data lake implementation, covering core principles, essential implementation steps, common use cases, key challenges, technology options, and proven strategies for avoiding the pitfalls that cause 70% of data lake projects to fail or underdeliver on their promises.
What Are the Core Principles of Data Lake Implementation?
Understanding these fundamental design principles ensures your data lake implementation delivers long-term value and avoids common architectural mistakes:
Centralized Storage for All Data Types
Data lakes eliminate data silos by providing a single repository for all organizational data, regardless of format or source. This centralization enables cross-functional analytics that were previously impossible when data remained trapped in departmental systems.
By understanding the differences and complementary use cases of data lakes and data warehouses, organizations can decide which workloads belong in which system to maximize efficiency.
Centralized storage reduces infrastructure costs by eliminating duplicate data across multiple systems and provides a single point of truth for enterprise information. Organizations can ingest everything from customer transaction logs and marketing campaign data to sensor readings and social media interactions without worrying about format compatibility.
Schema-on-Read Architecture
Traditional data warehouses require defining schemas during data loading (schema-on-write), which creates inflexibility when business requirements change. Data lakes implement schema-on-read, allowing raw data storage without predefined structure and applying schemas only when data is accessed for analysis.
This approach accelerates data ingestion since teams don’t need to spend weeks designing and implementing transformation logic before storing new data sources. Business users can explore data in its natural format and develop schemas based on actual analytical needs rather than anticipated requirements.
When paired with a real-time data warehouse, organizations can achieve both flexible storage and instant access to actionable insights.
Scalability and Cost Efficiency
Modern data lakes leverage cloud-native architectures that separate storage from compute, enabling independent scaling based on actual usage patterns. Organizations pay only for storage consumed and processing power used, rather than maintaining expensive fixed infrastructure.
This scalability becomes crucial as data volumes grow exponentially. Companies can start small with proof-of-concept implementations and scale to petabyte-level deployments without architectural rewrites or data migration projects.
Robust Metadata Management
Comprehensive metadata management transforms raw data dumps into discoverable, understandable assets. Effective data lakes capture technical metadata (schemas, lineage, quality metrics) and business metadata (definitions, context, usage patterns) automatically as data flows through the system, forming a solid data analytics framework that supports reliable insights and governance.
Without proper metadata management, data lakes quickly become “data swamps” where teams can’t find or trust available information. Investment in cataloging and documentation tools pays dividends through improved analyst productivity and data governance compliance.
Strong Data Governance & Security
Enterprise data lakes require governance frameworks that balance accessibility with security and compliance requirements. This includes role-based access controls, data classification systems, audit trails, and automated policy enforcement mechanisms.
Security considerations extend beyond access controls to include encryption at rest and in transit, data masking for sensitive information, and integration with enterprise identity management systems. Compliance with regulations like GDPR, HIPAA, or SOX requires systematic approaches to data retention, deletion, and audit trail maintenance.
Data Lake Implementation Checklist – 12 Essential Steps for Success
Following the below structured implementation approach significantly increases the likelihood of project success and business value delivery:
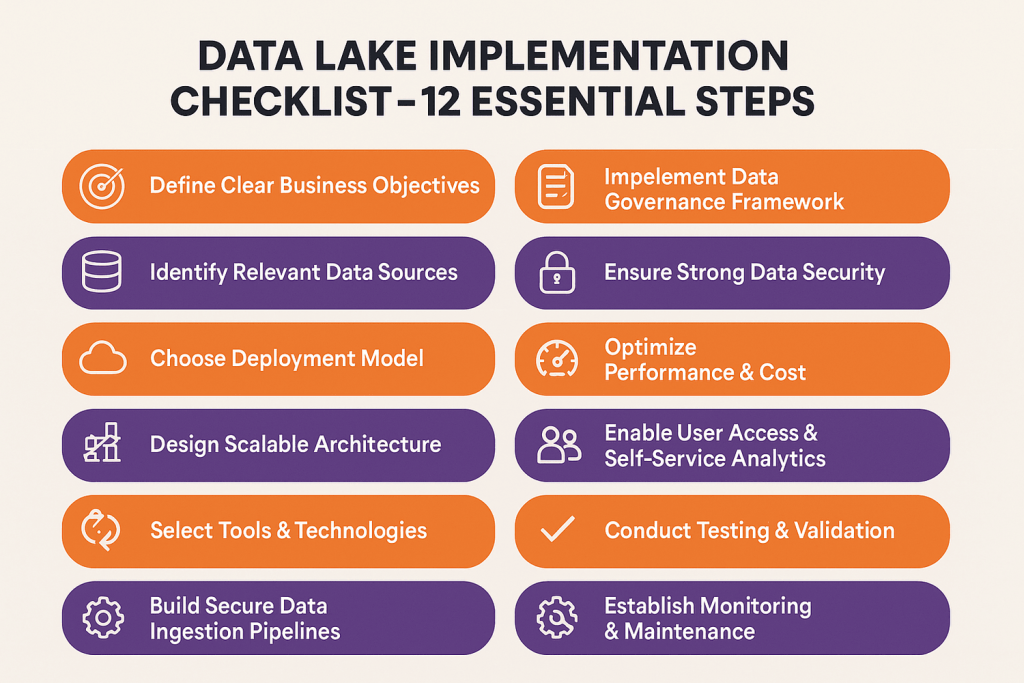
1. Define Clear Business Objectives
Successful data lake implementations begin with specific, measurable business objectives rather than vague goals like “become more data-driven.” Define concrete use cases such as reducing customer churn by 15%, improving supply chain efficiency by 20%, or enabling real-time fraud detection with sub-second response times.
Document expected ROI, success metrics, and stakeholder requirements before making technology decisions. This clarity helps prioritize features during implementation and provides benchmarks for measuring project success.
2. Identify All Relevant Data Sources
Conduct comprehensive data source inventory across your organization, including databases, applications, APIs, file systems, external providers, and streaming sources. Document data volumes, update frequencies, quality characteristics, and business criticality for each source.
Consider future data sources during planning to ensure your architecture can accommodate growth. Organizations often underestimate the complexity and variety of their data landscape, leading to architectural limitations discovered during implementation.
3. Choose Your Deployment Model
Evaluate deployment options including public cloud, private cloud, hybrid, and on-premises solutions based on security requirements, compliance needs, existing infrastructure, and cost considerations. Most organizations choose cloud-native implementations for scalable infrastructure that supports growth while reducing operational overhead.
Consider data residency requirements, network bandwidth limitations, and integration complexity with existing systems. Multi-cloud strategies provide vendor independence but add architectural complexity that may not justify the benefits for smaller implementations.
4. Design Scalable Architecture
Create architectural designs that accommodate current requirements while supporting future growth and evolving use cases. Design for horizontal scalability, implement tiered storage strategies, and plan for disaster recovery and business continuity scenarios.
Architecture decisions made early in implementation become difficult and expensive to change later. Involve experienced data architects who understand trade-offs between performance, cost, complexity, and maintainability.
5. Select Tools and Technologies
Choosing the right technology stack is integral to a successful data lake strategy. Evaluate options for data ingestion, storage, processing, cataloging, governance, and analytics based on technical capabilities, integration requirements, and long-term support considerations.
Avoid over-engineering solutions by selecting tools that match your team’s expertise and organizational maturity. Starting with proven, well-supported technologies reduces implementation risk and accelerates time to value.
6. Build Secure Data Ingestion Pipelines
Design data ingestion architecture that handles both batch and streaming data sources with appropriate error handling, data validation, and monitoring capabilities. Implement schema evolution support to handle changes in source systems without breaking downstream processes.
Include data quality checks during ingestion to catch issues early before they propagate through your analytics ecosystem. Document data lineage and transformation logic to support troubleshooting and compliance requirements.
7. Implement Data Governance Framework
Establish a data governance strategy with policies covering data ownership, quality standards, access controls, retention policies, and compliance requirements. Create data stewardship roles and responsibilities that extend beyond the IT organization to include business stakeholders.
Governance frameworks should be comprehensive enough to ensure data trustworthiness while remaining practical for day-to-day operations. Overly rigid governance processes can stifle innovation and user adoption.
8. Ensure Strong Data Security
Implement comprehensive security measures including network isolation, encryption, access controls, audit logging, and threat monitoring. Design security architecture that protects sensitive data while enabling legitimate business use cases.
Security should be built into the architecture from the beginning rather than added as an afterthought. Regular security assessments and penetration testing help identify vulnerabilities before they can be exploited.
Proper security helps prevent a data lake from becoming a data swamp, ensuring that only trusted, high-quality data is accessible for analysis.
9. Optimize for Performance and Cost
Implement storage tiering strategies that automatically move older or less-accessed data to cheaper storage classes. Use compression, partitioning, and indexing strategies to optimize query performance while controlling storage costs.
Monitor usage patterns and adjust resource allocation based on actual demand rather than peak capacity requirements. Cloud-native architectures enable fine-tuning that can significantly reduce operational expenses.
10. Enable User Access and Self-Service Analytics
Provide intuitive interfaces and tools that enable business users to access data without requiring deep technical expertise. Implement data catalogs, self-service query tools, and pre-built analytics templates that reduce time to insight.
User adoption determines project success more than technical capabilities. Investing in training, documentation, and support systems ensures that teams can leverage the full potential of a big data implementation and become productive quickly.
11. Conduct Testing and Validation
Implement comprehensive testing procedures covering data quality, performance, security, and user experience before production deployment. Include stress testing with realistic data volumes and query patterns to identify potential bottlenecks.
Establish validation criteria for each use case and verify that business objectives can be achieved with implemented solutions. Testing often reveals assumptions and requirements that weren’t apparent during design phases.
12. Establish Monitoring and Maintenance Processes
Implement monitoring systems that track data quality, system performance, user activity, and business metrics. Create alerting mechanisms that notify stakeholders when issues require attention.
Plan for ongoing maintenance activities including software updates, capacity planning, performance tuning, and governance policy updates. Data lakes require active management to remain valuable business assets.
What Are Common Use Cases for Data Lake Implementation?
Understanding typical use cases helps organizations identify opportunities where data lake architectures provide significant advantages over traditional solutions, such as:
Advanced Analytics & Data Science
Data lakes provide the raw material necessary for sophisticated analytics and machine learning initiatives. Data scientists can access historical data for training models, experiment with feature engineering approaches, and iterate rapidly without waiting for traditional ETL data transformation processes.
Organizations use data lakes to build predictive models for customer behavior, optimize marketing campaigns, detect anomalies in operational data, and automate decision-making processes. The flexibility to combine diverse data sources enables insights that wouldn’t be possible with traditional data warehouse architectures.
Business Intelligence & Reporting
While data warehouses excel at structured reporting, data lakes can supplement traditional BI with access to unstructured and semi-structured data sources. Modern BI tools can query data lakes directly, enabling business intelligence reporting that combines traditional metrics with social media sentiment, customer support interactions, and operational logs.
This expanded data access enables more comprehensive business dashboards and eliminates blind spots that exist when reporting relies only on structured transactional data.
Customer 360 & Personalization
Creating comprehensive customer profiles requires combining data from multiple touchpoints including websites, mobile apps, customer service interactions, purchase history, and third-party demographic information. Data lakes provide the storage capacity and flexibility needed to maintain these complete customer views, especially after a data warehouse to data lake migration.
Retailers use customer 360 initiatives to personalize shopping experiences, while financial institutions leverage complete customer profiles for risk assessment and product recommendations. Real-time personalization engines query data lakes to deliver contextually relevant experiences across all customer touchpoints.
Real-Time Monitoring & Alerts
Data lakes support streaming ingestion from operational systems, enabling real-time data collection, monitoring, and alerting capabilities. Organizations can detect and respond to operational issues, security threats, or business opportunities as they occur rather than discovering them in after-the-fact reports.
Manufacturing companies monitor equipment performance to predict maintenance needs, while e-commerce platforms track user behavior to identify conversion optimization opportunities in real-time.
Regulatory Compliance & Audit Readiness
Many industries require comprehensive data retention and audit trail capabilities that traditional systems struggle to provide cost-effectively. Data lakes can store all organizational data for extended periods while maintaining detailed lineage and access logs required for regulatory compliance.
Leveraging robust data and analytics solutions ensures organizations can meet these requirements efficiently and accurately.
Financial institutions use data lakes to maintain transaction records for regulatory reporting, while healthcare organizations store patient data to support research initiatives while maintaining HIPAA compliance.
Data Archiving & Cost-Efficient Storage
Data lakes provide cost-effective long-term storage for data that doesn’t require immediate access but may be valuable for future analysis. Organizations can implement tiered storage strategies that automatically move aging data to cheaper storage classes while maintaining accessibility.
This archiving capability eliminates the need to delete potentially valuable historical data due to storage cost constraints, preserving options for future analytics initiatives.
What Are Key Challenges In Implementing Data Lake and How to Overcome Them?
Understanding these common implementation challenges and proven solutions helps organizations avoid pitfalls that derail data lake projects:
Data Sprawl and Governance Issues
Without proper governance, data lakes can become unmanaged repositories where teams dump data without documentation or oversight. This data sprawl makes it impossible to find relevant information and creates compliance risks.
Overcome governance challenges by implementing data cataloging tools, establishing clear ownership roles, and creating policies for data ingestion and maintenance. Automated metadata capture and data lineage tracking help maintain visibility as data volumes grow.
Performance Bottlenecks
Poor query performance is another common aspect of data lake challenges, making interactive analytics difficult, especially when users attempt complex queries on large, unoptimized datasets. Performance issues often stem from inadequate partitioning strategies, lack of indexing, or inappropriate file formats.
Address performance challenges through proper data organization, implementing compression and columnar storage formats, and using query optimization techniques. Consider implementing data mart layers for frequently accessed datasets that require consistent high performance.
Security and Compliance
Data lakes often contain sensitive information from multiple sources, creating security challenges around access control, encryption, and audit trail maintenance. Compliance requirements vary by industry and geography, adding complexity to security architecture design.
Organizations can partner with experienced data engineering service providers to implement comprehensive security frameworks that include network isolation, encryption at rest and in transit, role-based access controls, and audit logging. Regular security assessments help identify and address vulnerabilities before they can be exploited.
Cost Management
Without proper monitoring and optimization, data lake storage and processing costs can spiral out of control. Organizations often underestimate the ongoing operational expenses associated with data lake maintenance and optimization.
Implement automated cost monitoring and optimization tools that track usage patterns and adjust resource allocation accordingly. Use tiered storage strategies and data lifecycle policies to control long-term storage costs while maintaining data accessibility.
Data Lake vs. Data Warehouse vs. Cloud Data Lakes – Key Differences
| Aspect | Data Lake | Data Warehouse | Cloud Data Lakes |
| Data Structure | Raw, unprocessed data in native formats | Structured, processed data with predefined schemas | Raw data with cloud-native processing capabilities |
| Schema Approach | Schema-on-read flexibility | Schema-on-write with rigid structure | Schema-on-read with elastic processing |
| Data Types | Structured, semi-structured, unstructured | Primarily structured relational data | All data types with advanced analytics support |
| Processing | Batch and stream processing | Batch processing optimized for queries | Serverless and auto-scaling processing |
| Cost Model | Storage and compute costs separate | High infrastructure and licensing costs | Pay-per-use with automatic optimization |
| Scalability | Highly scalable with cloud infrastructure | Limited by hardware capacity | Virtually unlimited with elastic scaling |
| Query Performance | Variable, depends on optimization | Optimized for consistent fast queries | High performance with intelligent caching |
| Implementation Time | Medium to long depending on complexity | Long due to ETL development requirements | Faster with managed services |
| Use Cases | Advanced analytics, ML, data science | Traditional BI, reporting, structured analysis | Modern analytics, AI/ML, real-time processing |
| Maintenance | Requires ongoing optimization and governance | High maintenance for ETL and infrastructure | Reduced maintenance with managed services |
What Are Top Technologies for Data Lake Implementation?
Selecting these appropriate technologies significantly impacts implementation success, ongoing operational costs, and long-term scalability:
Amazon Web Services
AWS provides comprehensive data lake capabilities through services like S3 for storage, Glue for ETL and cataloging, Athena for serverless queries, and Lake Formation for governance and security. The AWS ecosystem offers deep integration between services and extensive third-party tool support.
Organizations can leverage advanced data integration techniques with AWS Glue to streamline ingestion, transformation, and cataloging across diverse data sources.
AWS Lake Formation simplifies data lake setup with automated ingestion, cataloging, and access control capabilities. Organizations benefit from proven scalability and reliability that supports everything from small pilot projects to enterprise-scale implementations handling petabytes of data.
Microsoft Azure
Azure Data Lake Storage provides enterprise-grade security and performance with hierarchical namespace support that enables efficient data organization. Integration with Azure Synapse Analytics offers unified analytics capabilities that combine data integration, data warehousing, and analytics workloads.
Azure’s strength lies in seamless integration with existing Microsoft enterprise software and comprehensive compliance certifications that meet strict regulatory requirements. Power BI integration enables self-service analytics capabilities that business users can adopt quickly.
Snowflake
Snowflake’s cloud-native architecture separates storage from compute, enabling elastic scaling and pay-per-use pricing. The platform handles structured and semi-structured data natively, eliminating complex ETL processes for JSON, XML, and other formats.
Organizations can leverage Snowflake consulting services to optimize architecture, implement best practices, and ensure seamless integration with existing systems.
Snowflake excels at query performance through automatic optimization and intelligent caching. The platform’s sharing capabilities enable secure data exchange with partners and customers without complex integration projects.
Google Cloud Platform
Google Cloud offers BigQuery for serverless analytics, Cloud Storage for scalable data lake storage, and Dataflow for stream and batch processing. The platform leverages Google’s expertise in large-scale data processing and machine learning.
GCP’s strength in AI and machine learning makes it attractive for organizations prioritizing advanced analytics capabilities. Integration with TensorFlow and other Google AI tools simplifies machine learning model development and deployment.
How Folio3 Data Services Helps With Data Lake Implementation?
Organizations often struggle with data lake implementation complexity and lack internal expertise needed for successful deployment. Professional services can accelerate implementation while avoiding common pitfalls.
Folio3’s data lake implementation services begin with comprehensive assessment of existing data architecture, business requirements, and technical constraints. This assessment identifies optimal implementation approaches and helps prioritize features based on business value and technical feasibility.
Implementation services include architecture design, technology selection, security framework development, and governance policy creation. Experienced consultants bring proven methodologies and best practices learned from multiple implementations across different industries.
Migration services help organizations transition from existing data warehouses or legacy systems to modern data lake architectures. This includes data mapping, transformation logic development, and testing procedures that ensure business continuity during transitions.
Training and knowledge transfer ensure internal teams can maintain and optimize data lake implementations after deployment. Ongoing support services provide monitoring, optimization, and troubleshooting assistance while organizations develop internal expertise.
FAQs
What are the key steps in implementing a data lake?
The key steps include defining clear business objectives, identifying data sources, choosing deployment models, designing scalable architecture, selecting appropriate technologies, building secure ingestion pipelines, implementing governance frameworks, ensuring data security, optimizing performance and costs, enabling user access, conducting comprehensive testing, and establishing monitoring processes.
How long does it take to implement a data lake?
Implementation timelines vary significantly based on scope, complexity, and organizational readiness. Simple proof-of-concept implementations can be completed in 2-3 months, while enterprise-scale deployments typically require 6-18 months. Factors affecting timeline include data source complexity, governance requirements, integration needs, and team experience.
What are the common challenges in data lake implementation?
Common challenges include data sprawl and governance issues, performance bottlenecks, security and compliance requirements, and cost management. Organizations also struggle with user adoption, data quality maintenance, and integration with existing systems. Proper planning and experienced guidance help mitigate these challenges.
How does a data lake differ from a data warehouse?
Data lakes store raw data in native formats with schema-on-read flexibility, while data warehouses store processed data with predefined schemas. Data lakes handle all data types and support advanced analytics, while data warehouses optimize for structured reporting and traditional BI use cases.
Do I need a data lake if I already have a data warehouse?
Many organizations benefit from both technologies serving different purposes. Data warehouses excel at structured reporting and traditional BI, while data lakes enable advanced analytics, machine learning, and handling of unstructured data sources. The decision depends on specific use cases and analytical requirements.
What industries benefit the most from data lake implementation?
Industries with diverse data sources, regulatory requirements, or advanced analytics needs benefit most. This includes financial services for risk management and fraud detection, healthcare for research and patient analytics, retail for customer personalization, manufacturing for predictive maintenance, and technology companies for product optimization.
Can a data lake support real-time data processing?
Yes, modern data lakes support both batch and streaming data ingestion with real-time processing capabilities. Streaming technologies like Apache Kafka, AWS Kinesis, or Azure Event Hubs enable real-time data ingestion, while processing frameworks like Apache Spark provide real-time analytics capabilities.
How is data quality maintained in a data lake?
Data quality in data lakes is maintained through validation during ingestion, automated monitoring systems, data profiling tools, and governance policies. Unlike data warehouses that enforce quality during loading, data lakes implement quality checks at multiple stages and provide tools for ongoing quality assessment and improvement.
Conclusion
Data lake implementation offers transformative potential for organizations ready to unlock the full value of their data assets. Success requires systematic planning, appropriate technology choices, and commitment to ongoing governance and optimization. Organizations that follow proven implementation methodologies while avoiding common pitfalls create competitive advantages through better decision-making, operational efficiency, and innovation capabilities.
The key to successful data lake implementation lies in balancing technical capabilities with business requirements, ensuring that architectural decisions support both current needs and future growth. By partnering with Folio3 Data Services, they will give you proper planning, execution, and ongoing management that will make data lakes the strategic assets to enable advanced analytics, improve operational efficiency, and drive business innovation for years to come.



