

Big data architecture forms the backbone of modern analytics systems in enabling organizations to collect, store, and process massive volumes of data efficiently. It defines how data is moved from multiple sources through ingestion, storage, and processing layers to generate actionable insights that power business intelligence and informed decision-making.
Unlike traditional architectures built around single databases with fixed schemas and predictable data volumes, big data platform architecture embraces complexity. It handles structured, semi-structured, and unstructured data flowing from countless digital touchpoints, IoT devices, and enterprise systems, often in real time.
This shift has transformed how companies operate, demanding distributed systems that scale horizontally and support both batch and streaming data pipelines. Businesses today rely on robust big data solution architecture to drive innovation in detecting fraud in milliseconds, optimizing supply chains, predicting customer behavior, and personalizing digital experiences.
Without this foundation, legacy systems quickly crumble under data overload, leading to inefficiencies and delayed insights. Investing in the right big data architecture ensures scalability, flexibility, and performance. When designed strategically, it enables faster analytics, cost optimization, and sustainable growth in empowering organizations to stay competitive in an increasingly connected and data-centric world.
What Are the Key Components of Big Data Architecture?
A well-structured big data architecture is composed of multiple layers, each serving a critical role in managing the data lifecycle from ingestion to visualization. Together, these big data architecture components enable efficient data flow, transformation, and analysis within a scalable ecosystem.
1. Data Sources Layer
This is where data originates. Sources include transactional systems, IoT sensors, web and mobile applications, social media feeds, APIs, and enterprise databases. These sources generate structured, semi-structured, and unstructured data—often in both batch and streaming formats. A flexible big data platform architecture must support this variety to ensure seamless real time data collection from multiple touchpoints.
2. Data Ingestion Layer
The ingestion layer transfers data from various sources into the big data environment. Batch ingestion tools, such as Apache NiFi and AWS Glue, manage scheduled imports, while stream ingestion tools, including Apache Kafka and AWS Kinesis, handle real-time data flows. This layer also performs initial transformations, filtering, and validation to maintain consistency and readiness for downstream processing.
3. Data Storage Layer
This layer manages how data is stored and accessed. Data lakes (e.g., Amazon S3, Azure Data Lake) are ideal for large-scale, unstructured data, while data warehouses (e.g., Snowflake, Redshift) store structured data optimized for analytics. Additionally, NoSQL databases like MongoDB or Cassandra are used for high-velocity and schema-flexible workloads. Together, they ensure efficient storage across various layers of big data architecture.
4. Data Processing Layer
Processing frameworks, such as Apache Spark, Apache Flink, and Apache Hadoop, transform raw data into structured, usable formats. Batch processing supports large-scale computations, while stream processing enables real-time analytics for use cases like fraud detection or sensor monitoring. This stage is where data transformation in ETL pipelines converts raw inputs into business-ready insights.
5. Data Analysis and Serving Layer
This layer makes processed data accessible for querying, analytics, and decision-making. It powers dashboards, APIs, and reporting tools using engines like Presto or Google BigQuery. Through this, users can interact with clean, optimized datasets without managing the complexity of infrastructure.
6. Data Orchestration and Workflow Management
Orchestration tools, such as Apache Airflow or AWS Step Functions, automate complex workflows by scheduling jobs, managing dependencies, and ensuring a smooth data flow between systems.
Effective orchestration ensures that big data pipeline architecture remains consistent, reliable, and efficient.
7. Data Governance and Security Layer
Governance ensures data quality, compliance, and protection. This layer implements access control, data lineage, audit trails, and encryption to safeguard sensitive information, while meeting regulations such as GDPR and HIPAA.
8. Data Visualization and Consumption Layer
The final layer delivers actionable insights through dashboards, reports, and applications. Business intelligence tools like Tableau and Power BI allow users to visualize patterns, monitor KPIs, and make data-driven decisions easily.
What Are the Types of Big Data Architecture?
Different architectural patterns solve different problems. Choosing the right pattern depends on your use cases, latency requirements, and team capabilities.
1. Lambda Architecture
Lambda architecture combines batch and stream processing to provide both comprehensive historical analysis and real-time updates. It maintains two parallel paths, a batch layer that processes complete datasets and a speed layer handling recent data. The batch layer periodically processes all historical data to create accurate views.
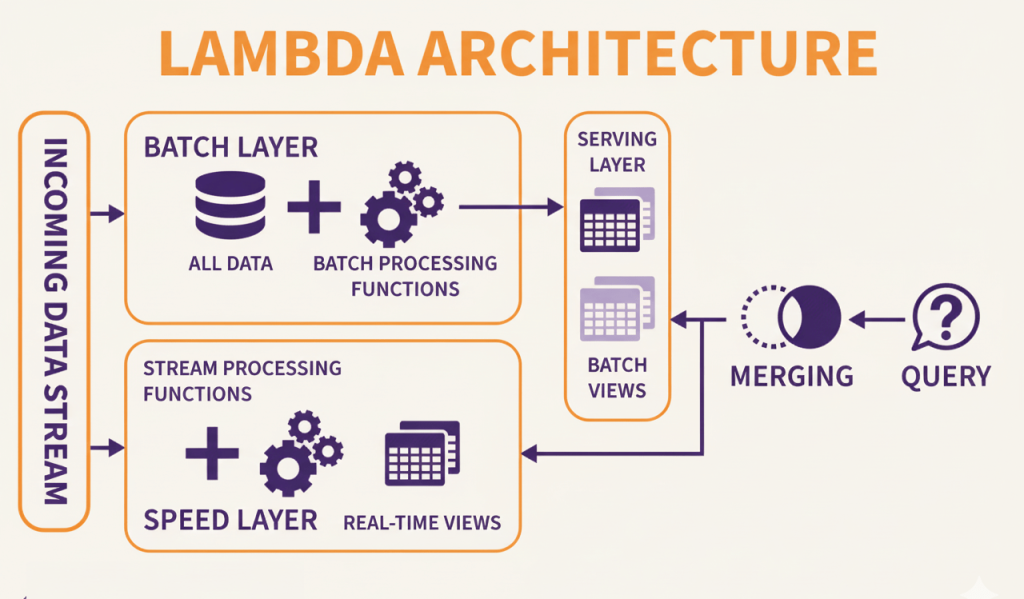
This process may run daily or weekly, generating aggregations and analytics that incorporate all records. Results are stored in a serving layer optimized for queries. The speed layer processes incoming data immediately, providing approximate results for recent events.
These compensate for batch processing lag, ensuring users see current data even though the batch layer is hours behind. A serving layer merges batch and speed results, presenting a unified view that combines historical accuracy with real-time updates.
Modern big data platforms often adopt variations of this model to balance scalability, reliability, and speed across analytics workloads.
- Pros: Provides both accurate historical analysis and real-time insights, handles data corrections through batch reprocessing, and has been proven at scale by companies like Twitter and LinkedIn.
- Cons: Maintains duplicate processing logic across batch and speed layers, increases operational complexity with two parallel systems, and requires more infrastructure than simpler architectures.
- Use cases: Applications requiring both real-time dashboards and accurate historical analytics, fraud detection systems that flag suspicious activity immediately while refining models on complete datasets, and recommendation engines that serve personalized suggestions updated continuously.
2. Kappa Architecture
Kappa architecture simplifies Lambda by eliminating the batch layer. All data flows through a unified stream processing pipeline, with historical data treated as a stream that can be replayed. Incoming events are stored in a durable log, such as Kafka, which retains messages for configurable periods.
Stream processing applications consume from this log, maintaining state and generating outputs. When you need to reprocess historical data, to fix bugs or implement new features, you replay the log through updated processing logic. This approach requires stream processing frameworks that can efficiently handle both real-time and historical data. Tools like Apache Flink excel at this pattern.
- Pros: Simpler architecture with a single processing paradigm, eliminates duplicate logic, easier to maintain and operate, natural fit for event-driven systems.
- Cons: Stream processing frameworks have steeper learning curves than batch tools. Maintaining large event logs increases storage costs, which is not ideal when batch processing is genuinely better suited for specific workloads.
- Use cases: Event-driven applications where all data is naturally streaming, real-time analytics platforms, systems where reprocessing requirements are frequent, and organizations standardizing on stream processing.
3. Hub-and-Spoke Architecture
Hub-and-spoke utilizes a central data lake or warehouse as the hub, with specialized systems serving as spokes and addressing specific use cases. Raw data is received in the hub, then transformed and pushed to spokes optimized for particular workloads.
The hub provides a single source of truth and centralized governance. Spokes might include a data warehouse for BI reporting, a search index for text queries, a graph database for relationship analysis, and ML feature stores for model training.
Data flows from sources into the hub through ingestion pipelines. Transformation jobs read from the hub, apply business logic, and write to the appropriate spokes. Each spoke optimizes for its use case without compromising the central repository.
- Pros: Centralized data governance and lineage, flexibility to add specialized systems, clear separation between storage and compute, and reduces data duplication across the organization.
- Cons: The hub can create bottlenecks, data movement between the hub and spokes introduces latency, and careful orchestration is required to keep the spokes synchronized.
- Use cases: Enterprises with diverse analytical needs, organizations consolidating siloed data sources, situations requiring specialized systems for different workloads, and companies prioritizing governance and compliance.
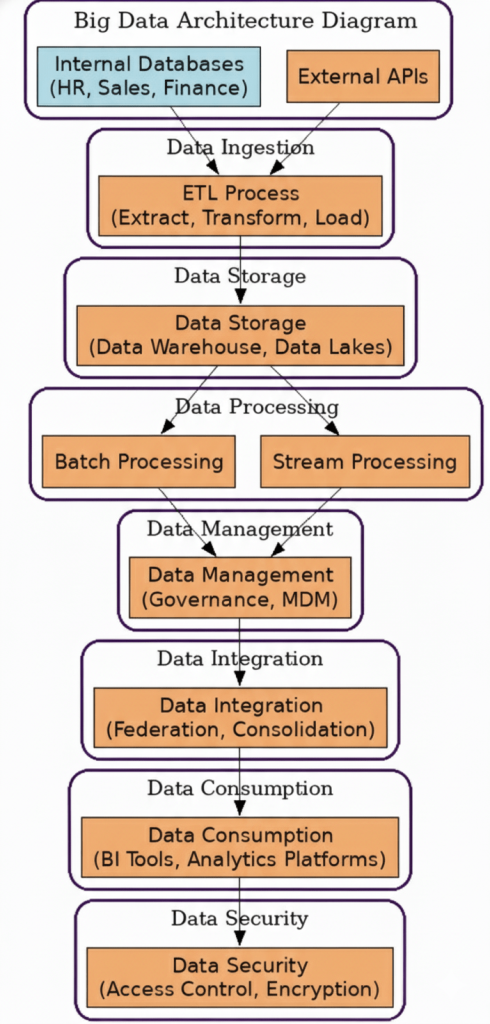
Big Data Architecture Diagram
A big data architecture diagram visually represents how data flows through an organization’s data ecosystem, connecting different components and layers within the architecture. It helps technical teams design efficient systems and enables business stakeholders to understand how raw data is transformed into actionable insights.A typical big data architecture diagram showcases every step of the data journey from collection to visualization illustrating how each layer interacts within the broader data solution architecture.
Benefits of Big Data Architecture
An efficient big data architecture offers significant advantages that drive performance, scalability, and innovation across modern enterprises. The benefits include:
1. High Performance and Parallel Computing
By using distributed processing, big data infrastructure architecture executes computations across multiple servers simultaneously, drastically reducing processing time from days to minutes. Frameworks like Apache Spark optimize performance by moving compute tasks closer to the data, minimizing network bottlenecks, and maximizing throughput.
2. Elastic Scalability
Cloud-based big data solution architectures scale resources automatically in response to demand. Businesses can expand their computing power during peak seasons, such as retail holidays, and scale back when demand drops. Storage and compute layers scale independently, reducing costs and eliminating over-provisioning.
3. Data-Driven Insights and Real-Time Analytics
Centralized data ecosystems unify information from all departments, ensuring consistent and accurate analysis. Real-time analytics enable instant decision-making, empowering fraud prevention, dynamic pricing, and personalized customer experiences.
A well-structured data analytics framework built on big data systems allows organizations to train machine learning models on massive datasets, unlocking deeper insights and predictive capabilities.
4. Freedom, Interoperability, and Competitive Edge
Modern big data platform architectures embrace open standards and APIs, allowing seamless integration of tools and avoiding vendor lock-in. This flexibility supports innovation while maintaining operational efficiency. Ultimately, businesses with advanced big data systems outperform competitors by making faster, smarter, and more informed decisions—turning data into a long-term strategic advantage.
Technology Stack for Big Data Architecture
A modern big data architecture relies on an integrated technology stack that supports large-scale data storage, processing, analysis, and visualization. Choosing the right big data architecture components ensures efficiency, scalability, and adaptability across the data lifecycle.
1. Data Storage Technologies
The foundation of most big data platform architectures is object storage such as Amazon S3, Azure Blob Storage, or Google Cloud Storage, which provides scalability, durability, and cost efficiency for massive datasets. For on-premises environments, distributed file systems like HDFS remain vital, as they enable data locality for faster processing.
Effective big data storage solutions also ensure seamless access, security, and performance across hybrid and cloud environments, supporting the growing demands of analytics-driven enterprises.
NoSQL databases (such as MongoDB, Cassandra, and Redis) handle flexible, high-velocity data, while data warehouses (like Snowflake, Redshift, and BigQuery) store structured data optimized for analytical queries using high-performance, columnar storage formats.
2. Data Processing Frameworks
Apache Spark is the cornerstone of modern big data analytics architecture, capable of handling both batch and real-time processing at scale.
Apache Flink provides low-latency stream processing, making it ideal for use cases that demand instant insights. Cloud-native services, such as AWS EMR, Azure HDInsight, and Google Dataproc, simplify management by running these frameworks as managed clusters.
3. Data Integration and Management Tools
Apache Kafka powers real-time ingestion and event streaming, while ETL tools like Apache NiFi, AWS Glue, and Azure Data Factory handle batch data flows.
Modern data integration techniques ensure seamless movement and transformation of information across diverse systems, maintaining consistency and accuracy at scale.
Orchestration tools such as Apache Airflow automate complex pipelines, manage dependencies, and ensure workflow reliability within the big data pipeline architecture.
4. Analytics, BI, and Infrastructure Tools
Query engines like Presto, Athena, and BigQuery enable SQL-based access to distributed data. Visualization platforms, such as Tableau, Power BI, and Looker, transform analytics into actionable insights.
Underpinning all layers, Kubernetes and Terraform support container orchestration, automation, and reproducible deployments, ensuring that your big data solution architecture remains scalable, flexible, and cloud-ready.
How Do You Design Big Data Architecture?
Designing an effective big data architecture involves creating a framework that not only meets current business needs but also scales effortlessly as data grows. A well-structured big data pipeline architecture ensures reliability, performance, and flexibility across every stage of the data lifecycle.
1. Requirements Assessment
Begin by clearly defining business goals, user needs, and the type of insights required. Identify the characteristics, volume, velocity, and variety of data, along with the associated latency expectations. Determine whether your system must support real-time, near real-time, or batch analytics. Document compliance and security obligations early, as these influence data storage, access, and geographic boundaries. This assessment ensures that your big data solution architecture aligns with your organization’s priorities.
2. Architecture Design Principles
A successful big data platform architecture is built on resilience, scalability, and modularity.
- Design for failure: Distributed systems are prone to faults; incorporate replication, retries, and failover mechanisms.
- Separate concerns: Use specialized technologies for storage, processing, and serving layers.
- Embrace immutability: Append-only data stores simplify consistency and auditing.
- Optimize for reads: In analytical systems, prioritize query speed over write performance with efficient formats and caching.
3. Choosing the Right Architecture Pattern
Select an architecture pattern that fits your analytical and operational requirements:
- Lambda Architecture: Combines batch and streaming layers for both historical and real-time analysis.
- Kappa Architecture: Simplifies pipelines for event-driven, streaming-only environments.
- Hub-and-Spoke Architecture: Centralizes governance while supporting diverse analytics needs.
Avoid over-engineering, start simple and iterate as your data and team maturity evolve.
4. Data Modeling Strategies
Schema design determines query performance and flexibility. In data lake architecture, organizing files by logical partitions (e.g., date or category) facilitates efficient data retrieval and scalable analytics. In warehouses, star schemas optimize for analytics, while snowflake schemas reduce redundancy. Use slowly changing dimensions (Type 2) to maintain accurate historical context.
5. Network and Infrastructure Design
Efficient networking is vital for smooth data flow. Co-locate compute and storage resources to minimize latency, segment networks for security, and replicate critical data across regions for disaster recovery. Infrastructure as code (IaC) tools, such as Terraform, ensure reproducibility and consistent deployments across environments.
How Does Big Data Architecture Differ from Traditional Data Architecture?
The paradigm shift from traditional to big data architectures reflects fundamental changes in data characteristics and business needs. Traditional architectures optimize for ACID transactions and data consistency.
They work well for operational systems recording financial transactions, inventory updates, or customer orders. Big data architectures prioritize availability and partition tolerance, accepting eventual consistency for the benefits of scale and performance.
| Aspect | Traditional Data Architecture | Big Data Architecture |
| Data Volume | Gigabytes to terabytes | Terabytes to petabytes and beyond |
| Scaling Approach | Vertical (more powerful hardware) | Horizontal (more machines) |
| Data Structure | Structured, predefined schemas | Structured, semi-structured, unstructured |
| Processing Model | Centralized | Distributed across cluster nodes |
| Storage Type | Relational databases, SAN | Object storage, distributed file systems |
| Schema Design | Schema-on-write (defined before loading) | Schema-on-read (applied during analysis) |
| Hardware | Expensive specialized servers | Commodity hardware or cloud services |
| Processing Timing | Batch (scheduled jobs) | Batch, streaming, and real-time |
| Data Integration | ETL (Extract, Transform, Load) | ELT (Extract, Load, Transform) |
| Query Language | SQL | SQL, NoSQL, programming APIs |
| Fault Tolerance | RAID, backup, failover | Replication, distributed consensus |
| Cost Model | High upfront CapEx | Operational OpEx, pay-per-use |
What Are Real-World Use Cases of Big Data Architecture?
Here are some real-world case studies that demonstrate how organizations have deployed big data architecture across various domains:
1. Retail & E-Commerce Analytics
Walmart’s Predictive Analytics for Inventory Optimization
Walmart utilizes a robust big data architecture that combines Hadoop, Spark, and Cassandra to process over 2.5 petabytes of data per hour. This enables predictive analytics for demand forecasting, optimizing stock levels across thousands of stores. The system integrates sales data, weather forecasts, and local events to anticipate customer demand, minimizing overstocking and stockouts.
2. Financial Services & Fraud Detection
PayPal’s Real-Time Fraud Detection System
PayPal utilizes a real-time streaming data architecture, built with Kafka, Spark, and TensorFlow, to analyze billions of transactions daily. Machine learning models detect unusual activity within milliseconds, preventing fraudulent payments. The architecture supports both batch and streaming analytics, ensuring accuracy without latency.
3. Healthcare & Life Sciences
Johns Hopkins Predictive Patient Care
Johns Hopkins Hospital employs a big data architecture integrating EHR data, IoT health monitors, and clinical research datasets through Hadoop and Spark. Through healthcare big data analytics, the hospital uses advanced models to predict patient deterioration and optimize resource allocation, reducing ICU stays and improving care outcomes.
4. Telecommunications & Network Optimization
Verizon’s Network Performance Analytics
Verizon utilizes a cloud-based big data architecture that combines Hadoop, Kafka, and AI-driven analytics to process terabytes of network logs in real-time. This helps identify congestion patterns, predict outages, and optimize bandwidth allocation for better service quality.
5. Manufacturing & Supply Chain Optimization
General Electric’s Industrial IoT Platform (Predix)
GE’s Predix platform collects real-time sensor data from turbines, engines, and manufacturing lines. Using Kafka, Spark, and AWS, it analyzes performance trends, predicts equipment failures, and schedules proactive maintenance, thereby reducing downtime and improving operational efficiency.
6. Smart Cities & IoT Applications
Barcelona’s Smart City Data Platform
Barcelona implemented a big data-powered IoT platform to manage urban infrastructure, integrating data from traffic sensors, waste systems, and energy grids. Using Hadoop, Kafka, and real-time analytics dashboards, city officials optimize energy consumption, reduce congestion, and improve public services.
Common Challenges in Big Data Architecture
Challenges like distributed complexity, quality management, and scalability often arise during implementation. Continuous monitoring and robust data engineering best practices are essential to maintain efficiency and reliability.
1. Data Quality Issues
Poor-quality data undermines analytics accuracy and decision-making. Errors, missing fields, and inconsistent formats from multiple sources can cascade through pipelines. To prevent this, implement data validation at ingestion, define data contracts, and monitor quality metrics continuously to detect schema drift or anomalies early.
2. Distributed System Complexity
Distributed environments introduce challenges like network failures, data inconsistency, and debugging difficulties across clusters. Tools such as Prometheus, Grafana, and Jaeger enhance observability through real-time monitoring and tracing. Adopting chaos engineering practices strengthens resilience against unpredictable failures.
3. High Infrastructure Costs
Processing and storing petabytes of data can be expensive. Cloud egress fees, inefficient queries, and poor data formats all contribute to inflated costs. Optimize by using compression, right-sizing compute resources, archiving cold data, and leveraging reserved capacity for predictable workloads. Continuous cost monitoring ensures scalability without overspending.
4. Real-Time Processing Challenges
Real-time systems must handle state management, exactly-once processing, and backpressure. Falling behind in stream processing can lead to stale analytics. Frameworks like Apache Flink and Kafka Streams help maintain low-latency performance. Testing under realistic loads ensures systems can manage streaming data efficiently and reliably.
Best Practices for Designing Big Data Architecture
Designing a robust big data architecture requires striking a balance among scalability, governance, and adaptability. Following proven best practices helps minimize risk while ensuring long-term value.
1. Start Small and Scale
Begin with a specific, high-impact use case, such as fraud detection or personalized recommendations, to demonstrate value early. Avoid over-engineering a full-scale data platform upfront; instead, use iterative development to validate designs and refine processes as needed. Pilot architectures on limited datasets to uncover issues before scaling to production.
2. Choose the Right Tools
Select technologies based on maturity, documentation, and community support—not trends. Opt for managed services such as AWS Glue, BigQuery, or Azure Synapse when operational efficiency outweighs customization needs. Standardize core tools to reduce complexity while maintaining the flexibility to adapt to new requirements as they emerge.
3. Implement Strong Governance
Governance ensures data quality, security, and traceability. Define dataset ownership, document schemas, and establish lineage tracking to monitor transformations. Apply least-privilege access controls and maintain audit trails to meet compliance standards. Automate data validation and anomaly detection to catch quality issues early.
4. Optimize Performance Continuously
Monitor performance metrics regularly as data volumes grow. Tune queries, partitioning schemes, and caching strategies for efficiency. Utilize indexing and pre-aggregation to minimize latency in frequently executed queries. Periodically review storage formats and compression algorithms for cost and performance improvements.
5. Design for Flexibility and Scalability
Keep components loosely coupled through well-defined APIs to allow easy upgrades or replacements. Prioritize horizontal scalability, where adding nodes improves performance linearly, ensuring systems evolve without costly overhauls. A flexible architecture adapts to changing business needs while maintaining speed, reliability, and cost-efficiency.
Future Trends in Big Data Architecture
Big data architecture is rapidly evolving, driven by advances in AI, edge computing, quantum processing, and sustainability goals. The next generation of architectures will prioritize intelligence, speed, and environmental responsibility.
1. AI and Machine Learning Integration
Machine learning is now integral to modern data ecosystems. Feature stores and MLOps frameworks streamline model management, while real-time inference enables predictions to be directly integrated into data pipelines, thereby minimizing latency.
Emerging technologies like data extraction AI further enhance automation by capturing valuable insights from complex, unstructured data sources. Patterns such as retrieval-augmented generation (RAG) and vector databases enable smarter, context-aware analytics powered by generative AI.
2. Edge Computing and Big Data
As IoT expands, processing data closer to the source is essential. Edge computing reduces bandwidth costs and latency by handling real-time analytics on devices or regional nodes, while central clouds focus on long-term storage and model training. With 5G networks, architectures can now support ultra-low-latency applications, such as smart manufacturing and autonomous vehicles.
3. Quantum Computing Impact
Quantum computing is set to revolutionize big data by solving complex problems classical systems struggle with—such as optimization, encryption, and simulation. Future architectures will adopt hybrid models, dynamically routing workloads between quantum and classical processors based on the suitability of each task.
4. Sustainability and Green Computing
With rising energy demands, data-driven organizations are turning to eco-efficient architectures. These include renewable-powered data centers, optimized hardware, and carbon-aware workload scheduling that prioritizes the availability of green energy. Sustainable data practices are becoming not just ethical, but essential for long-term scalability.
FAQs
What is big data architecture, and why is it important?
Big data architecture is a framework that manages the collection, storage, and analysis of large-scale data. It’s important because it enables organizations to derive actionable insights from massive datasets efficiently and securely.
What are the main components of big data architecture?
The main components of big data architecture include data sources, ingestion, storage, processing, analysis, governance, and visualization layers, each ensuring a smooth data flow and reliable analytics.
How does big data architecture differ from traditional data architecture?
Unlike traditional data architecture, big data architecture handles unstructured and real-time data at scale, offering high flexibility, distributed processing, and cloud-based scalability.
What is the role of a data ingestion layer in big data architecture?
The data ingestion layer in a big data architecture captures and transfers data from multiple sources into the system for processing and analysis in real-time or batch mode.
What are the common types of big data architecture?
Common types of big data architecture include Lambda, Kappa, and Data Lakehouse architectures—each supporting different real-time, batch, or hybrid data processing needs.
What tools are used in big data architecture?
Big data architecture commonly utilizes tools such as Apache Hadoop, Apache Spark, Apache Kafka, AWS, and Snowflake to facilitate efficient data ingestion, transformation, and analytics.
How do you design a scalable big data architecture?
Design a scalable big data architecture by using distributed systems, modular components, and cloud-based storage to handle growing data volumes without compromising performance.
What are the benefits of big data architecture?
The benefits of big data architecture include improved decision-making, real-time analytics, cost efficiency, data integration, and enhanced business intelligence across all departments.
What are the challenges in implementing big data architecture?
Challenges in big data architecture include data quality issues, system complexity, infrastructure costs, and ensuring governance, security, and compliance across distributed systems.
How is big data architecture evolving with AI and cloud technologies?
Big data architecture is evolving through AI-driven automation, cloud scalability, and advanced analytics tools that enhance performance, accuracy, and real-time data processing.
Conclusion
Big data architecture is the backbone of intelligent decision-making, enabling organizations to harness data for growth, agility, and innovation. As businesses embrace cloud, AI, and analytics-driven transformation, having the right framework is critical to maintaining scalability and performance.
Folio3’s Data Services provide end-to-end support, from design and integration to optimization, helping you build a secure, future-ready data ecosystem. With expertise in platforms such as AWS, Azure, and Snowflake, Folio3 ensures that your data is accessible, reliable, and actionable.
Partner with Folio3 today and transform your data into a strategic advantage!



