

Most AI initiatives fail not because of the model, but because the data isn’t ready. This single truth is the biggest hurdle businesses face when trying to use artificial intelligence.
The numbers tell a stark story. According to Gartner, up to 60% of AI projects that are unsupported by “AI‑ready” data may be abandoned by 2026.
Poor data quality costs the U.S. economy an estimated $3.1 trillion annually. These numbers are more than statistics; they reflect real projects that stalled, budgets that were wasted, and opportunities that were missed.
The problem starts before the AI work even begins. Data scientists spend around 45% of their time just cleaning and organizing data. That’s nearly half their workweek spent on preparation instead of innovation.
This guide will demystify AI-ready data. We’ll explain what it is, why it’s crucial for your business, and provide a clear, step-by-step roadmap to get your data ready for AI.
What is AI-ready data?
AI-ready data is information that is properly prepared and structured so that artificial intelligence and machine learning models can understand and use it effectively. Think of it as preparing ingredients before you start cooking a complex meal. You wouldn’t throw whole, unwashed vegetables into a pot and expect a gourmet dish. Similarly, AI models need data that is clean, organized, relevant, and in a format they can process.
Raw data collected from business operations, customer interactions, or sensors is often messy. It can have missing values, incorrect entries, duplicate records, and inconsistent formats. AI models trained on such “dirty” data produce inaccurate or biased results, a concept known as “garbage in, garbage out.”
AI-ready data, on the other hand, has been through a rigorous preparation process. It is accurate, complete, consistent, and well-documented. It has been cleansed of errors, transformed into a suitable format, and often labeled to provide context for the AI model. This preparation ensures that the AI can learn the correct patterns and make reliable predictions or decisions, which is the entire point of using AI in the first place. Without this foundational work, any investment in AI technology is built on shaky ground.
How Do You Know Data is AI-Ready?
You can identify AI-ready data by checking for several key characteristics that signal its quality and usability for machine learning models. It’s not just about the data itself but also about the systems and processes that surround it. When you can confidently say “yes” to these attributes, you are well on your way to having a truly valuable asset for your AI projects.
First, AI-ready data is accessible. This means your data scientists and AI systems can easily find and retrieve the information they need, when they need it, without navigating complex silos or access restrictions.
Second, it is reliable and accurate. The data should be free from errors, duplicates, and inconsistencies, reflecting a true picture of what it represents.
Third, it is relevant to the problem you are trying to solve. You might have perfectly clean data about weather patterns, but it won’t help you predict customer churn.
Finally, the data must be well-documented. Anyone using the data should be able to understand what each field means, where the data came from, and how it has been transformed. This documentation, or metadata, is essential for building trust and ensuring the data is used correctly.
Core Building Blocks of AI-Ready Data
To truly understand what makes data ready for AI, it helps to break it down into its fundamental components. These five building blocks form the foundation of any successful AI initiative.
Data quality
This refers to the accuracy, completeness, and reliability of your data. High-quality data is free from errors, typos, and missing values, ensuring that AI models learn from correct information.
Data consistency
This means your data is uniform across all a company’s systems. For example, a customer’s name and address should be recorded in the same format everywhere, preventing confusion and duplication.
Data integration
This is the process of combining data from different sources into a single, unified view. It allows AI models to analyze comprehensive datasets to uncover deeper insights from various business areas.
Organizations can enhance this process by using tools that enable enterprise AI search, making it easier to locate and access relevant data across systems without disrupting workflows.
Data governance & security
This involves setting rules for how data is accessed, used, and protected. Strong governance ensures data is handled responsibly, ethically, and in compliance with regulations like GDPR or CCPA.
Data documentation & metadata
This is the “data about the data.” It includes information on data sources, definitions, and transformations. Good documentation helps data scientists understand and trust the data they are using.
5 Key Steps to Make Your Data AI-Ready
Transforming raw data into an AI-ready asset is a systematic process. Following these five essential steps will help you build a solid foundation for your machine learning projects and initiatives.
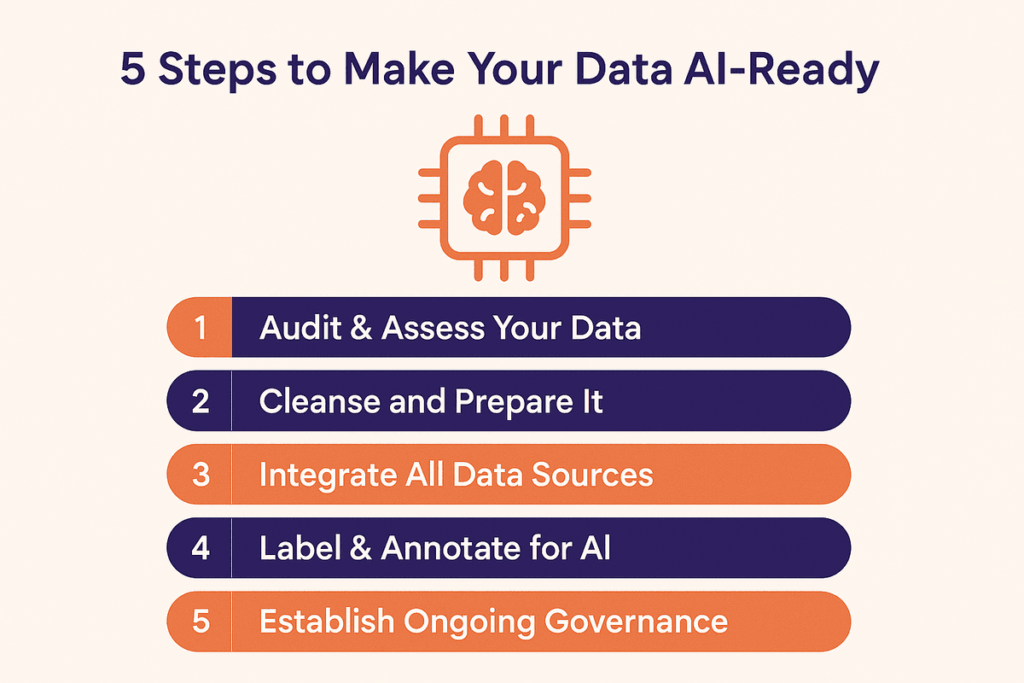
Step #1: Conduct a data audit & assessment
Before you can fix your data, you need to understand what you have. A data audit involves creating an inventory of all your data sources, whether they are in databases, spreadsheets, or cloud storage.
During this phase, you assess the current state of your data. Ask critical questions: Where does our data live? Is it structured (like in tables) or unstructured (like text and images)?
How much of it is duplicated or outdated? What are the most common quality issues? This initial assessment provides a clear picture of the work ahead and helps you prioritize which datasets to focus on first.
Understanding and organizing these datasets is especially important when implementing AI demand forecasting, as accurate and complete data is the foundation for reliable predictions.
Step #2: Cleanse and preprocess data
This is where the heavy lifting happens. Data cleansing, or data scrubbing, is the process of fixing or removing incorrect, corrupted, or incomplete data.
This includes handling missing values by either filling them in with reasonable estimates or removing the records. It also involves correcting typos, standardizing formats (e.g., making sure all dates are in `YYYY-MM-DD` format), and removing duplicate entries. Preprocessing goes a step further by transforming the data into a format suitable for AI models.
This might involve normalization (scaling numerical data to a standard range) or encoding categorical data (turning text labels like “Red,” “Green,” “Blue” into numbers). This step is critical for ensuring the AI model isn’t misled by formatting issues or errors.
Step #3: Integrate Data from Multiple Sources
Most businesses store data in different places. Customer information might be in a CRM, sales data in an ERP system, and website traffic in a web analytics tool. To get a complete picture, you need to bring this data together. Data integration involves combining these disparate datasets into a single, cohesive dataset.
This can be done through processes like ETL (Extract, Transform, Load), where data is extracted from its source, transformed into a consistent format, and loaded into a central repository like a data warehouse or data lake. An integrated dataset allows AI models to find relationships and patterns that would be invisible when looking at each source in isolation.
Step #4: Label & annotate data for AI models
For many types of AI, especially supervised machine learning, the model needs to be trained on labeled data. Data labeling is the process of adding informative tags or annotations to your data to provide context. For example, to train an AI to recognize cats in pictures, you would need to label thousands of images, marking which ones contain a cat.
To train a sentiment analysis model, you would label customer reviews as “positive,” “negative,” or “neutral.” This step is often manual and time-consuming but is absolutely essential. The quality of the labels directly impacts the accuracy of the AI model. High-quality, consistent labeling is the key to teaching your AI to make the right decisions.
Step #5: Ensure Ongoing Data Governance
Making your data AI-ready isn’t a one-time project; it’s an ongoing commitment. Data governance establishes the rules, policies, and processes for managing data throughout its lifecycle.
This includes defining who has access to what data, ensuring compliance with privacy regulations like GDPR, and setting standards for data quality.
A strong governance framework ensures that your data remains clean, secure, and trustworthy over time. It creates a system of accountability and prevents the high-quality data you’ve prepared from degrading back into a messy state. Think of it as the maintenance plan that keeps your AI engine running smoothly.
Real-World Use Cases of AI-Ready Data
When data is properly prepared for AI, it unlocks powerful capabilities across every part of a business. These practical applications demonstrate how AI-ready data moves from a technical concept to a driver of real-world value.
Predictive Analytics
Walmart uses AI to forecast product demand across its stores, analyzing historical sales data, seasonal trends, and local events. This helps them optimize inventory levels, reducing waste while ensuring products are available when customers need them.
By applying advanced predictive analytics models to this data, Walmart can make more accurate inventory and stocking decisions, reducing waste while ensuring products are available when customers need them.
Personalized Recommendations
Netflix’s recommendation engine analyzes viewing patterns from over 230 million subscribers to suggest content. The system processes billions of data points daily, requiring meticulously cleaned and structured data on user preferences, watch history, and engagement metrics. Around 80% of content watched on Netflix comes from these AI-driven recommendations.
Fraud Detection & Prevention
PayPal’s AI systems analyze billions of transactions in real-time, using machine learning models trained on historical fraud patterns. Their AI reviews multiple data points per transaction—device information, location, purchase history—to flag suspicious activity within milliseconds, preventing fraudulent transactions before they complete.
Operational Efficiency
UPS’s ORION system (On-Road Integrated Optimization and Navigation) uses AI to optimize delivery routes for its 60,000+ drivers. By analyzing clean data on addresses, traffic patterns, delivery time windows, and package volume, the system saves UPS approximately 100 million miles and 10 million gallons of fuel annually.
Customer Insights & Segmentation
Starbucks uses AI through its Deep Brew platform to analyze customer purchase history, preferences, and behavior across its mobile app and loyalty program.
These insights support a range of use cases of generative AI for retail, such as personalized marketing messages, customized menu recommendations, and targeted promotions that have significantly increased customer engagement and loyalty.
AI Model Training
Tesla’s Autopilot trains its computer vision models on billions of miles of real-world driving data collected from its fleet. The quality and diversity of this training data—captured from cameras, sensors, and various driving conditions—directly determines the system’s ability to recognize objects, predict behavior, and make safe driving decisions.
Must-have Tech for AI-Ready Data
Preparing data for AI requires a set of powerful tools designed to store, manage, and transform information at scale. This technology stack forms the backbone of any modern AI ready data management strategy.
Data Storage solutions
This includes data warehouses for structured data and data lakes for raw, unstructured data. Modern solutions like cloud-based AI-ready data storage (e.g., Amazon S3, Google Cloud Storage) offer scalable and flexible options, making it easier for organizations to manage and optimize their big data storage needs effectively.
Data Integration Platforms
Tools like Talend, Informatica, or Fivetran help automate the process of pulling data from multiple sources and combining it into a single location, which is crucial for creating a unified view.
Companies often rely on experienced teams with strong data engineering expertise to ensure these integrations are robust, scalable, and maintain data quality for AI-ready workflows.
Data Cleaning & Preprocessing Tools
Platforms such as Trifacta or OpenRefine help data professionals identify and fix errors, remove duplicates, and standardize formats in large datasets, often using an intuitive, visual interface.
Data Labeling & Annotation Tools
For supervised learning, tools like Labelbox, Scale AI, or Amazon SageMaker Ground Truth provide platforms for human annotators to accurately label images, text, and other data types to train AI models.
Data Governance & Security Tools
Solutions like Collibra or Alation help organizations manage their data assets. They provide a data catalog, define policies, and track data lineage to ensure compliance and build trust in the data.
Challenges in Preparing AI-Ready Data
The path to achieving AI-ready data is not always smooth. Organizations often encounter several common obstacles that can slow down or derail their AI initiatives if not addressed proactively.
Large, Diverse Datasets
The sheer volume and variety of data today can be overwhelming. Managing terabytes or petabytes of data from different systems, in various formats (text, images, video), requires sophisticated infrastructure and expertise.
Data Privacy & Compliance
Regulations like GDPR and CCPA impose strict rules on how personal data can be handled. Organizations should consider conducting an AI data readiness assessment to evaluate whether their datasets meet compliance standards and are structured appropriately for AI initiatives, including anonymizing or protecting sensitive information.
Unstructured or Incomplete Data
Much of the world’s data is unstructured—think emails, social media posts, and documents. Extracting value from this data is complex. Additionally, dealing with missing values without introducing bias is a constant challenge.
Data quality & Consistency
Ensuring data is accurate and consistent across the entire organization is a persistent battle. Data silos often lead to different departments having conflicting versions of the same information, making it hard to create a single source of truth.
Best Approaches for AI Data Readiness
To overcome the challenges, businesses should adopt a set of best practices that promote a sustainable and effective data readiness strategy. These approaches help maintain data quality and usability over the long term.
Continuous Monitoring & Validation
Data quality is not static. Implement automated systems to continuously monitor data streams for anomalies, errors, or drift. Regular validation checks ensure that the data remains reliable as it changes over time.
Regular Updates & Cleaning
Schedule routine data cleaning processes to address new errors and inconsistencies as they appear. Just like regular maintenance on a car, this prevents small issues from becoming major problems down the road.
Documentation & Metadata Management
Maintain a central, accessible data catalog that documents what each dataset contains, where it came from (its lineage), and how it has been transformed. Using AI tools in data engineering can help automate this process, making it easier for teams to track data quality, detect anomalies, and find the information they need efficiently.
Standardized Data Formats
Establish and enforce organization-wide standards for how data is formatted and stored. This simplifies data integration and ensures that data from different systems can work together seamlessly without extensive transformation.
Access Control & Governance
Implement a robust governance framework with clear roles and responsibilities. Use role-based access controls to ensure that only authorized personnel can view or modify sensitive data, protecting it from misuse. Adopting strong enterprise data governance practices also helps maintain consistency, compliance, and trust across all datasets within the organization.
How to Build an AI-Ready Culture
Technology and processes are only part of the solution. A successful AI strategy requires a cultural shift where the entire organization values and prioritizes high-quality data in its day-to-day operations.
Leadership Support
Change starts at the top. When executives champion the importance of data quality and invest in the necessary resources, it sends a powerful message that data is a strategic asset for the entire company.
Employee Training
Educate employees across all departments on basic data hygiene principles. Teach them the importance of accurate data entry and how their work contributes to the organization’s broader AI goals.
Data-driven Decision Making
Encourage teams to base their decisions on data rather than intuition alone. When people see the tangible benefits of using clean data to drive better outcomes, they are more likely to contribute to maintaining it.
Collaboration & Communication
Break down data silos by fostering collaboration between IT, data teams, and business units. Open communication ensures everyone is aligned on data standards and works together to solve data quality issues.
AI Data Readiness Simplified by Folio3
Achieving AI-ready data can seem complex, but you don’t have to do it alone. At Folio3, we specialize in transforming your raw data into a strategic asset, clearing the path for successful AI implementation. We simplify the entire journey, from initial assessment to ongoing governance, allowing you to focus on innovation instead of data wrangling. Our approach is built on years of expertise and a deep understanding of what it takes to make your data AI-ready.
We provide a full suite of services designed to address every stage of the data preparation lifecycle:
- Comprehensive Data Assessment: We start by auditing your existing data landscape to identify quality issues, gaps, and opportunities.
- Smart Data Cleansing & Preparation: Our experts use advanced tools and techniques to clean, standardize, and enrich your data, ensuring it’s accurate and reliable. This process includes AI-powered data extraction from diverse sources, allowing us to capture critical information efficiently and reduce manual effort.
- Seamless Data Integration: We break down data silos, integrating information from disparate sources into a unified, analysis-ready format.
- Intelligent Data Labeling & Annotation: We manage the critical process of data labeling to create high-quality training datasets for your specific AI models.
- Secure & Compliant Data Practices: We help you establish robust data governance and security protocols to protect your data and ensure regulatory compliance.
Future Directions in AI Data Readiness
The field of data preparation is constantly advancing. As AI technology becomes more sophisticated, the methods we use to get data ready will also evolve, becoming more automated, intelligent, and efficient.
Automated Data Preparation
Expect to see more AI-powered tools that can automatically detect and fix data quality issues, suggest relevant transformations, and even generate labels, significantly reducing manual effort.
Organizations adopting a generative AI implementation framework will find it easier to standardize these processes and ensure consistent, high-quality outputs across datasets.
Real-time Data Processing
As businesses demand faster insights, the focus will shift from batch processing to real-time data pipelines. This will enable AI models to make decisions based on the most current information available.
Data Privacy & Ethics Focus
Techniques like federated learning and differential privacy will become more common, allowing organizations to train AI models on sensitive data without directly accessing or exposing it, enhancing both privacy and security.
Augmented Analytics Tools
These tools will use AI to guide users through data exploration and analysis. They will automatically surface insights, recommend visualizations, and make it easier for non-experts to work with complex data.
FAQs
What does it mean for data to be AI-ready?
AI-ready data is information that has been cleaned, organized, and structured in a way that machine learning algorithms can easily process. It is high-quality, consistent, well-documented, and relevant to the specific problem the AI is trying to solve.
Why is AI-ready data important for machine learning projects?
It’s the foundation of any successful AI project. AI models learn from the data they are given; if the data is inaccurate, incomplete, or biased, the model’s predictions and decisions will also be flawed. The “garbage in, garbage out” principle applies directly here.
How do I assess if my data is ready for AI?
You can assess your data by performing a data audit. This involves checking for key attributes like completeness (are there missing values?), accuracy (are there errors?), consistency (are formats standardized?), and timeliness (is the data up to date?). Profiling tools can help automate this assessment.
What are the key steps to make data AI-ready?
The main steps are: 1) Auditing and assessing your current data. 2) Cleansing and preprocessing to fix errors and format the data. 3) Integrating data from various sources into a unified view. 4) Labeling and annotating the data for supervised learning models. 5) Establishing ongoing data governance to maintain quality.
Which tools help make data ready for AI and machine learning?
A range of tools can help, including data integration platforms (e.g., Talend, Fivetran), data cleaning tools (e.g., Trifacta), data labeling services (e.g., Scale AI, Labelbox), and data governance platforms (e.g., Collibra). Cloud providers like AWS, Google Cloud, and Azure also offer comprehensive suites of data preparation tools.
Conclusion
The journey to artificial intelligence begins not with an algorithm, but with data. AI-ready data is not a technicality; it is the bedrock of any successful, reliable, and ethical AI system. While the process of transforming raw, messy information into a clean, structured, and trustworthy asset requires effort, the payoff is immense. It unlocks the true potential of machine learning, enabling businesses to make smarter predictions, automate complex processes, and deliver personalized experiences.
By understanding the core building blocks, following a systematic preparation process, and fostering a culture that values data, any organization can bridge the gap between having data and using it effectively. Investing in making your data AI-ready is a direct investment in the future success and relevance of your business in an increasingly data-driven world.
Partnering with Folio3 Data Services can accelerate this journey, providing expert guidance, tools, and frameworks to ensure your data is AI-ready and optimized for maximum impact. Investing in making your data AI-ready is a direct investment in the future success and relevance of your business in an increasingly data-driven world.



