

We live in a data-driven world, and businesses are increasingly turning to big data to gain insights, make informed decisions, and drive growth. Big data offers many opportunities, but the implementation process can be complex and challenging.
Whether you’re a business analyst, big data architect, or developer, understanding the step-by-step process of big data implementation is crucial to the success of your project.
This guide will walk you through the essential steps to successfully implement big data into your project and how big data can transform your business.
What is Big Data Implementation?
Big data implementation refers to integrating big data technologies and practices into an organization’s existing systems to collect, store, process, and analyze large volumes of data.
The global big data technology market is experiencing significant growth, with projections indicating an increase from $397.27 billion in 2024 to $1,194.35 billion by 2032, representing a compound annual growth rate (CAGR) of 14.8% during the forecast period.
The goal is to extract valuable insights to inform business decisions, optimize operations, and drive competitive advantage.
Why Big Data Implementation is Essential
Big data implementation empowers organizations to harness vast amounts of structured and unstructured data to make informed decisions. According to aimultiple, 69% of companies report better strategic decisions, and 52% gain a deeper understanding of their customers through big data initiatives. Furthermore, businesses leveraging big data achieve an 8% increase in revenues and a 10% reduction in costs, making it a critical driver of profitability and operational efficiency.
These benefits underline why industries ranging from retail to healthcare and finance are prioritizing big data as a cornerstone of their digital transformation strategies.
Key Components of a Big Data Solution
To successfully implement big data, it’s essential to understand the key components of a comprehensive big data solution.
Each element plays a vital role in ensuring that data is effectively managed, processed, and utilized.
1. Data Sources
Data sources are the origin points of the data you intend to collect and analyze. These sources can be internal, such as transactional databases and customer relationship management (CRM) systems, or external, such as social media, IoT devices, and third-party data providers. The diversity and volume of data sources directly impact the complexity and scalability of your big data solution.
Leveraging data strategy consultation can help identify and integrate these diverse sources effectively.
2. Data Storage
Storing vast amounts of data is a critical aspect of data implementation. The data storage solution should be scalable, secure, and capable of handling structured, semi-structured, and unstructured data.
Standard storage solutions include Hadoop Distributed File System (HDFS), cloud-based storage services like Amazon S3, and NoSQL databases such as MongoDB and Cassandra. Snowflake consulting services can optimize these storage solutions to ensure they align with your business requirements.
3. Data Processing
Data processing involves transforming raw data into a format that can be analyzed. This step is crucial for extracting meaningful insights from the data.
Processing can be done in real-time, in batch mode, or using a combination of both. Tools like Apache Spark, Apache Flink, and Hadoop MapReduce are commonly used for big data processing, depending on the project’s specific needs. Data engineering consulting services play a key role in designing and managing these processing frameworks.
4. Analytics and Visualization Tools
Once the data is processed, it must be analyzed to uncover patterns, trends, and insights. This analysis can be performed using various tools and techniques, such as machine learning algorithms, statistical analysis, and data mining.
Visualization tools like Tableau, Power BI, and Google Data Studio are crucial in presenting the results in an easily understandable format, allowing stakeholders to make informed decisions. A comprehensive data analytics strategy ensures that these tools are effectively utilized to derive actionable insights.
5. Data Governance and Security
Data governance and security are essential to ensure the data is accurate, consistent, and protected from unauthorized access. This involves setting up policies and procedures for data management, compliance with regulations (such as GDPR), and implementing security measures like encryption and access controls. A solid data protection strategy is crucial to maintaining the integrity and confidentiality of your data.
6. Infrastructure
The infrastructure for big data analytics implementation includes the hardware, software, and network resources needed to support data processing and storage. This can involve on-premise servers, cloud-based services, or a hybrid approach.
The choice of infrastructure depends on factors like budget, scalability, and the specific requirements of your big data project.
How to Implement Big Data Analytics: Key Steps
Implementing big data requires a systematic approach to ensure that all aspects of the solution are properly addressed. If you’re wondering how to create big data, below are the key steps involved in the process:
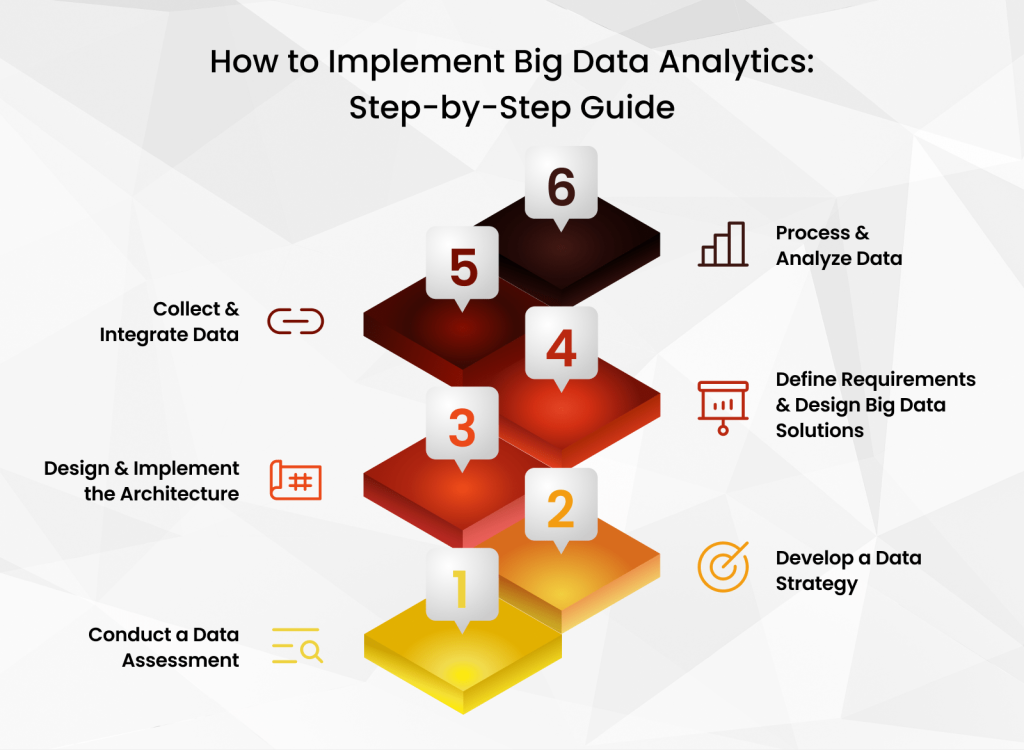
Step 1: Conduct a Data Assessment
Before diving into big data, conducting a comprehensive data assessment is crucial. This involves identifying the types of data your organization collects, evaluating the quality of this data, and determining how it can be used to meet your business objectives.
A thorough data assessment helps understand the project’s scope and sets the foundation for the subsequent steps in how to build big data solutions.
Step 2: Develop a Data Strategy
A well-defined data strategy is essential for successful implementation. This strategy should outline the goals of your big data initiatives, the types of data to be collected, and the methods for processing and analyzing this data. It should also address key considerations such as data governance, compliance, and technologies. The strategy should answer key questions about how to make big data work effectively for your organization.
Step 3: Design and Implement the Architecture
Designing a scalable and flexible architecture is critical to handling large volumes of data efficiently. The architecture should include data storage solutions, processing frameworks, and analytics tools that align with your business needs. Big data architects play a key role in this step, ensuring the architecture can support future growth.
- Creation of Data Models Representing All Data Objects in Big Data Databases
This involves creating data models that represent all the data objects to be stored in big data databases.
- Defining Associations Between Data Objects to Understand Data Flows
This step defines the associations between data objects to clearly understand how data flows within the system.
- Planning Data Collection, Storage, and Processing for Various Formats
This includes planning how data of various formats will be collected, stored, and processed within the upcoming solution.
- Developing a Data Quality Management Strategy
This step involves developing a data quality management strategy to ensure the integrity and reliability of the data.
- Implementing Data Security Mechanisms and Controls
This includes implementing data security mechanisms such as data encryption, user access control, and redundancy to protect the data.
- Designing an Optimal Big Data Architecture for the Entire Data Lifecycle
This involves designing an optimal big data architecture that supports the entire data lifecycle within the solution, including data ingestion, processing, storage, and analytics.
Step 4: Effective Requirements and Designing Big Data Solutions
In this step, it’s essential to define the requirements for your big data solution, including data sources, processing needs, and desired outcomes.
Collaborating with business analysts and stakeholders is necessary to ensure the solution meets the organization’s needs. Once the requirements are established, the solution can be designed, considering factors like scalability, security, and cost-effectiveness. A well-thought-out data monetization strategy can be developed at this stage to maximize the financial value of your data assets.
- Identification of Various Data Types to Be Collected
This includes identifying data types such as SaaS data, Supply Chain Management (SCM) records, operational data, images, and video.
- Estimation of Data Volume
This step involves estimating the volume of data collected and managed within the solution.
- Establishing Required Data Quality Metrics
This involves setting up the necessary data quality metrics to ensure the accuracy and reliability of the data.
- Planning for Integrations with Existing IT Infrastructure
This step includes planning how the new solution will integrate with the existing IT infrastructure, if applicable.
- Addressing Security and Compliance Requirements
This involves addressing security and compliance requirements such as HIPAA, PCI DSS, and GDPR to ensure the solution meets regulatory standards.
- Selection of the Most Suitable Technology Stack for the Solution
This step includes selecting the most appropriate technology stack that will support the needs and goals of the solution.
Step 5: Data Collection and Integration
Data collection involves gathering data from various sources, both internal and external. This data must then be integrated into your big data solution, ensuring it is in a consistent format and ready for processing.
Data integration tools like Apache NiFi, Talend, and Informatica can help streamline this process, enabling seamless data flow across different systems. Data migration strategy should be planned carefully to ensure a smooth transition from legacy systems to new data platforms.
Step 6: Data Processing and Analysis
Once the data is collected and integrated, it’s time to process and analyze it. This involves applying data processing frameworks to clean, transform, and prepare the data for analysis.
Advanced analytics techniques, such as machine learning and predictive modeling, can then be used to extract insights and drive decision-making. Big data developers and scientists are typically involved in this step, ensuring the analysis is accurate and aligned with the business objectives.
Sourcing Models for Big Data Solution Implementation
Implementing a big data solution is a multifaceted process that requires careful consideration of various sourcing models. Your approach can significantly impact your big data initiatives’ success, cost, and scalability.
Whether you handle everything in-house, outsource to a third-party vendor, or blend both methods with a hybrid approach, each model has advantages and challenges.
Understanding these sourcing models is crucial for aligning your big data strategy with your organization’s goals, resources, and long-term vision.
In this section, we will explore the key sourcing models available for big data solution implementation, helping you make an informed decision that best suits your needs.
1. In-House Implementation
In-house implementation involves building and managing the big data solution internally. This approach gives the organization full control over the project, allowing for customization and alignment with specific business needs.
However, it requires significant investment in infrastructure, technology, and skilled personnel, such as big data architects, developers, and analysts.
2. Outsourcing to a Vendor
Outsourcing involves partnering with a third-party vendor to design, develop, and manage the big data solution. This cost-effective approach eliminates the need for in-house expertise and infrastructure.
Vendors typically offer specialized knowledge and experience, which can accelerate the implementation process. However, outsourcing may lead to less control over the project and potential data security and privacy concerns.
3. Hybrid Approach
A hybrid approach combines elements of both in-house implementation and outsourcing. Organizations may develop certain aspects of the solution internally while outsourcing others, such as data processing or analytics.
This approach balances control, cost, and flexibility, allowing organizations to leverage external expertise while retaining control over critical components.
The Benefits of Implementing Big Data
Implementing big data into your project offers many benefits that can transform your organization and provide a competitive edge.
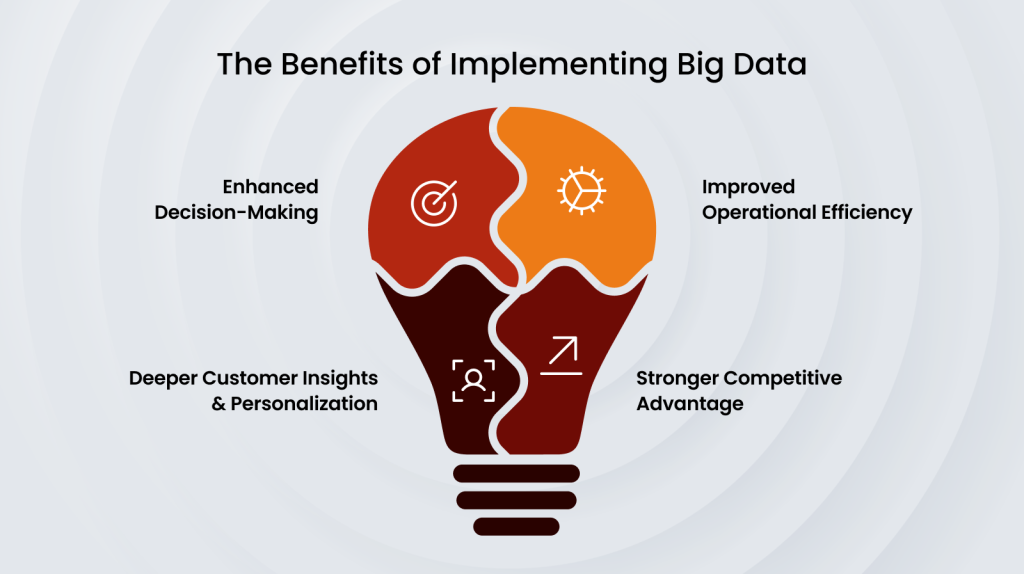
Enhanced Decision-Making
Big data provides organizations with actionable insights to improve decision-making at all levels. Businesses can identify trends, uncover hidden patterns, and predict future outcomes by analyzing large volumes of data. This enables more informed decisions, reducing risks and increasing the likelihood of success.
Improved Operational Efficiency
Big data can help optimize business processes, streamline operations, and reduce costs. Organizations can identify inefficiencies, automate repetitive tasks, and improve resource allocation by analyzing operational data. This increases productivity and makes the business more agile.
Customer Insights and Personalization
In a competitive market, big data can be a game-changer. By leveraging big data and plans for big computing, businesses can differentiate themselves from competitors. Big data initiatives can help optimize operations, enhance customer experiences, and lead to innovative products and services, enabling organizations to stay ahead of the curve.
Competitive Advantage
In a competitive market, big data can be a game-changer. Businesses can differentiate themselves from competitors by leveraging data to gain insights, optimize operations, and enhance customer experiences. Big data initiatives can lead to innovative products, services, and business models, helping organizations stay ahead of the curve.
FAQs
What is the implementation of big data?
Big data implementation refers to integrating big data technologies into an organization’s systems to collect, process, and analyze large volumes of data, enabling better decision-making and operational efficiency.
How do you implement big data in a company?
Implementing big data in a company involves conducting a data assessment, developing a data strategy, designing the architecture, collecting and integrating data, and processing and analyzing the data to extract insights.
Is big data challenging to implement?
Implementing big data can be complex due to the need for specialized technology, infrastructure, and expertise. However, it can be successfully implemented with a clear strategy, the right tools, and proper planning.
Final Words
Big data implementation is a powerful tool for organizations looking to maximize the potential of data-driven decision-making. By following the steps outlined in this guide and partnering with Folio3 Data services experts, you can get over the complexities of implementation and unlock its benefits.
So, whether you implement big data in-house, outsource, or take a hybrid approach, the key is to have a clear strategy and the right resources to ensure success!



