

Have you ever wondered how data moves seamlessly across your organization, from collection to delivery? Behind the scenes, data integration architecture plays a critical role in making that possible. It acts as the blueprint for how data from multiple systems is gathered, transformed, and delivered where it’s needed — ensuring everything runs smoothly and efficiently.
At its core, it’s the design framework that connects different data sources into a unified system, making information accessible, reliable, and ready for analysis. Without it, businesses would struggle with inconsistent data, slow decision-making, and missed opportunities.
The speed and accuracy of data flow directly impact a company’s ability to stay competitive, serve customers better, and innovate faster. According to Gartner, by 2025, 70% of organizations are expected to move away from traditional batch processing and adopt real-time data integration, highlighting just how vital a flexible, robust architecture has become.
Beyond simply connecting databases, a structured data integration framework brings significant benefits — from improving data quality and governance to enabling real-time analytics and smarter business strategies.
Data integration architects design the backbone that supports this structure, ensuring that the data integration layer is optimized for speed, scalability, and security. Visual tools like a data integration diagram or a data integration flow diagram help map this process, offering clear insights into how data journeys across complex systems.
In this ultimate guide, we’ll dive deeper into the essentials of data integration architecture, explore its benefits, and show why mastering it is no longer optional for modern businesses — it’s a strategic necessity.
Core Components of Data Integration Architecture
A strong data integration architecture is more than just connecting systems—it’s a thoughtful design that ensures data flows efficiently, securely, and in the right format across your organization. To understand how it all comes together, it’s important to look closely at its essential building blocks. Each component plays a distinct role in shaping a reliable and scalable integration framework.
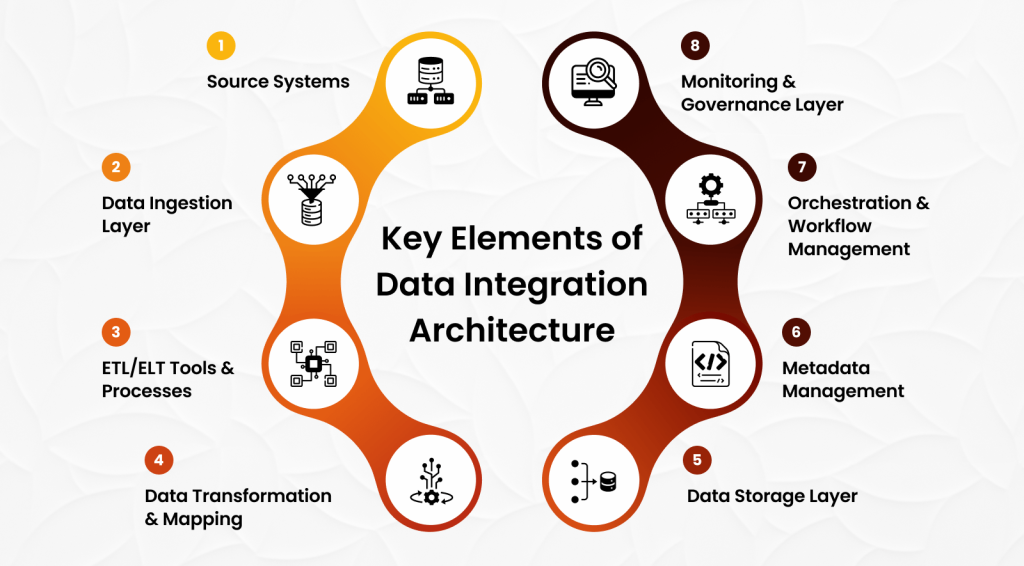
1. Source Systems
The starting point of any data journey is the source systems. These are the original platforms and technologies where data is created or collected. Source systems can range from traditional databases to cloud-based SaaS applications like Salesforce, ERP systems, marketing automation tools, or even real-time streams from IoT devices. To unlock the full value of this distributed data, organizations rely on robust data integration services that connect, consolidate, and prepare data from these diverse sources for downstream analytics, reporting, and AI-driven insights.
Modern businesses often rely on a hybrid mix of on-premises and cloud sources, creating the need for a flexible data integration architecture that can handle both structured and unstructured data efficiently. Without properly understanding the variety and nature of source systems, creating a seamless data integration flow diagram becomes nearly impossible.
2. Data Ingestion Layer
Once the sources are identified, the next critical piece is the data ingestion layer. This layer is responsible for pulling in data from various sources into the integration system. There are two primary modes of ingestion:
- Batch ingestion: Collects and processes data at scheduled intervals (e.g., hourly, nightly).
- Streaming ingestion: Pulls data in real-time as it is generated.
3. ETL/ELT Tools & Processes
At the heart of data integration is the process of preparing the data for use, and that’s where ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) come into play. These processes are typically designed and optimized by experienced data engineering service providers to ensure data is clean, structured, and ready for analysis, enabling smarter business decisions and seamless data flow across systems.
- ETL processes extract data from sources, transform it into a usable format, and then load it into storage.
- ELT extracts and loads the raw data first, then transforms it within the target storage system (such as a data warehouse or data lake).
Choosing between ETL and ELT depends on the data volume, latency requirements, and existing infrastructure. Modern cloud-native ETL/ELT tools automate much of this, offering scalability, flexibility, and error-handling features that data integration architects rely on to maintain reliable systems.
4. Data Transformation & Mapping
Simply moving data isn’t enough—it must be cleaned, formatted, and mapped properly so it can be used effectively. Data transformation and mapping involve converting data into a consistent format, standardizing units, merging duplicate entries, and aligning different datasets to create a unified view.
Without strong transformation rules, downstream systems would face inconsistencies, errors, and operational inefficiencies. Think of this stage as translating multiple languages into a common one that your analytics platforms and business users can understand clearly.
5. Data Storage Layer
Once data is transformed, it needs a reliable place to live. The data storage layer can take multiple forms:
- Data Lakes: Store massive amounts of raw, unstructured, or semi-structured data.
- Data Warehouses: Hold structured, cleaned data optimized for querying and reporting.
- Data Lakehouses: Combine the flexibility of data lakes with the governance and performance features of warehouses.
6. Metadata Management
Metadata—the data about your data—plays a silent yet crucial role in data integration architecture. Metadata management involves tracking information such as data origin, format, usage history, and transformation rules.
Good metadata management improves transparency, boosts data quality, and helps compliance efforts (like GDPR or HIPAA). It also empowers teams to quickly understand what data they have and how it can be used, which is invaluable for driving business insights.
7. Orchestration & Workflow Management
Data integration isn’t a one-time event—it’s an ongoing, dynamic process that involves multiple tasks happening in sequence or in parallel. Orchestration and workflow management tools help automate these complex processes, ensuring that tasks like ingestion, transformation, and loading happen in the correct order and under the right conditions.
Advanced orchestration also supports error recovery, scheduling, dependency management, and system scalability. Tools like Apache Airflow, Talend, or Informatica are popular choices for setting up robust workflows that keep data pipelines running smoothly without constant manual intervention.
8. Monitoring & Governance Layer
Finally, no data integration architecture is complete without a strong monitoring and governance layer. This layer keeps a close eye on the health, performance, and security of data pipelines. It ensures that issues like data loss, duplication, or unauthorized access are detected and addressed promptly.
Strong governance practices—such as role-based access control, auditing, and compliance reporting—not only build trust in the system but also protect the organization from legal and financial risks.
Real-time monitoring dashboards, alerting systems, and auditing trails are all integral parts of this layer, providing visibility into how data is flowing through your architecture.
Types of Data Integration Architectures
Choosing the right type of data integration architecture is crucial for building a system that meets your organization’s needs for speed, flexibility, and scale. Each architecture model offers a different approach to how data is collected, moved, and made available for use. As part of comprehensive Data Architecture Services, understanding these integration models is essential to designing a robust, scalable, and future-ready data environment. Let’s take a closer look at the major types of data integration architectures and how they fit into today’s data-driven world.
Centralized Architecture
In a centralized architecture, all data from various source systems is collected into a single repository, such as a data warehouse or a large database. From here, it can be accessed, processed, and analyzed.
This approach is often visualized using a straightforward data integration diagram, where arrows point from different systems to one central hub. The centralized method simplifies data management because everything lives in one place, making it easier for data integration architects to maintain governance, security, and quality.
However, centralized architectures can face challenges as organizations scale, especially when handling real-time data from modern SaaS applications and IoT devices. Still, for many enterprises with structured data needs and strong governance requirements, it remains a reliable choice.
Federated Architecture
Unlike centralized systems, a federated architecture doesn’t move all data into a single storage system. Instead, it creates a layer that connects different databases and source systems without physically consolidating the data.
In a federated setup, data remains within its source system, but users can query it as if it were in one unified database. This reduces duplication, speeds up integration for diverse systems, and keeps storage costs down.
Federated models are particularly useful in large organizations where different departments maintain their own databases but still need a unified view for analytics. Data integration architects often employ federated models when rapid access to distributed data is more important than consolidating it.
One downside is that querying across different systems can lead to performance bottlenecks, especially when real-time data or complex transformations are needed.
Data Virtualization Architecture
Data virtualization architecture takes the concept of federation one step further. Instead of physically moving or copying data, virtualization provides a real-time, unified view of data across multiple systems through a virtual layer.
With data virtualization, users can access data stored across different sources (cloud services, on-prem databases, SaaS apps) without worrying about where it physically resides. The virtual layer handles all the complexities behind the scenes—query translation, optimization, and result aggregation.
For businesses that need agility and flexibility, data virtualization offers an attractive solution. It’s often depicted in a data integration flow diagram where user queries pass through a virtualization layer that connects multiple source systems.
However, because the underlying data remains dispersed, virtualization might not be the best fit for heavy analytics workloads that require massive joins, aggregations, or complex transformations.
Hub-and-Spoke Model
The hub-and-spoke model provides a structured way to manage integration across a growing number of systems. In this architecture, a central hub manages connections between all other systems (the spokes).
Each spoke—whether it’s a CRM, ERP, database, or third-party app—communicates with the hub rather than directly with each other. This design simplifies the number of integrations needed: instead of connecting every system to every other system (which grows exponentially), each system only connects to the hub.
This model is highly scalable and helps enforce consistent rules for data transformation, validation, and security. It’s particularly useful when setting up centralized governance in complex IT environments.
However, the hub becomes a critical point of failure. If it experiences issues, the entire integration flow can be disrupted. This is why modern data integration architects design redundant hubs or use cloud-based integration platforms that offer high availability.
Modern Cloud-Native Architectures
As cloud adoption has soared, modern cloud-native architectures have become the standard for organizations seeking agility, scalability, and resilience. These architectures are designed to integrate data across SaaS platforms, public clouds, private clouds, and on-premises systems—all while handling real-time and batch data flows.
Cloud-native integration leverages microservices, serverless functions, APIs, and event-driven frameworks to move and transform data at scale. Tools like AWS Glue, Azure Data Factory, and Google Cloud Dataflow are examples that support cloud-native integration models.
A modern data integration layer in cloud-native environments often uses streaming ingestion, cloud ETL/ELT tools, AI-enhanced transformation, and scalable storage options like cloud data lakes or lakehouses.
One of the biggest advantages of cloud-native architectures is flexibility. Businesses can scale up during peak times, reduce costs during slow periods, and integrate new data sources quickly without reengineering the entire system. Security, governance, and monitoring features are built into the cloud platforms, making it easier to manage complex data integration workflows.
At the same time, cloud-native architectures require skilled data integration architects to design systems that avoid vendor lock-in and ensure data remains portable and secure across environments.
Architectural Patterns & Approaches in Data Integration
When designing a data integration architecture, it’s not just about picking the right systems; it’s also about choosing the best patterns and approaches for how data moves, transforms, and serves business needs. Let’s explore some of the most important architectural patterns that data integration architects rely on today.
1. ETL vs. ELT
One of the oldest and most critical decisions in data integration design is whether to use ETL (Extract, Transform, Load) or ELT (Extract, Load, Transform).
- ETL pulls data from source systems, transforms it into the required format, and then loads it into a target system like a data warehouse. This method works best when transformation rules are complex, and you want tight control before the data lands in storage.
- ELT, on the other hand, extracts data and immediately loads it into the target system, where the transformation happens later. Modern cloud-based data warehouses like Snowflake and BigQuery make ELT highly attractive because they offer massive computing power to transform data after loading.
2. Batch vs. Real-Time Streaming
Another critical decision is whether to process data in batches or stream it in real-time.
- Batch processing collects data over a set period (e.g., every hour or every day) and then processes it all at once. It’s easier to manage, costs less, and fits well for reporting or analytical needs where immediate updates aren’t necessary.
- Real-time streaming processes data as soon as it’s created. This is crucial for use cases like fraud detection, customer personalization, or monitoring IoT devices where seconds matter.
3. API-Led Integration
Modern applications, especially cloud-native and SaaS platforms, rely heavily on APIs (Application Programming Interfaces) to expose their data. API-led integration organizes and connects data systems using a series of APIs — typically broken down into system APIs, process APIs, and experience APIs.
This structure allows different teams to independently build, manage, and reuse integrations. With API-led integration:
- New services or applications can be integrated faster.
- Changes in one system don’t ripple across the entire architecture.
- Data integration becomes more modular, scalable, and secure.
API management platforms like MuleSoft and Apigee provide full lifecycle management, helping teams ensure that APIs are discoverable, governed, and reusable. In any modern data integration layer, API-led strategies are essential for achieving speed, flexibility, and resilience, especially in dynamic business environments.
4. Event-Driven Architecture (EDA)
Event-Driven Architecture (EDA) is another key pattern that’s reshaping how data integration happens. Instead of systems pulling data at scheduled times (polling), EDA pushes updates as events occur. An event could be a new order placed, a customer updating their profile, or a sensor sending temperature readings. These events are captured, processed, and acted upon in real-time.
EDA uses components like message queues, event buses, and streaming platforms (e.g., Apache Kafka, AWS EventBridge) to enable scalable, asynchronous communication between systems.
For organizations that need high responsiveness, scalability, and decoupling between services, EDA fits perfectly into the broader data integration architecture. It ensures that as soon as something happens, it’s instantly reflected across all connected systems — a major advantage over traditional, delay-prone integration patterns.
5. Data Mesh and Data Fabric
As data environments become increasingly complex, newer approaches like Data Mesh and Data Fabric have emerged to address organizational challenges.
- Data Mesh shifts data ownership from centralized teams to domain-specific teams (e.g., sales, marketing, operations). Each team manages their own data products, ensuring better quality, relevance, and speed. Data mesh emphasizes decentralization, self-serve infrastructure, and treating data as a product.
- Data Fabric, in contrast, focuses on creating a unified architecture by weaving together different data management tools and platforms through automation, metadata-driven intelligence, and integration. Data fabric abstracts the complexity of where and how data is stored, allowing users and applications to access it seamlessly.
Key Design Considerations
Building an effective data integration architecture requires more than connecting systems — it demands careful attention to key design principles that ensure long-term success.
- Scalability and Performance
Scalability and performance are critical. As data volumes grow, your architecture must handle increasing loads without degrading speed or reliability. Planning for horizontal scaling and optimizing your data integration layer are essential steps.
- Data Quality and Validation
Data quality and validation should never be afterthoughts. Poor data input leads to flawed insights. Integrating validation checks at the ingestion stage and during transformations ensures accurate, reliable outputs.
- Security and Compliance
Security and compliance are non-negotiable. With regulations like GDPR and HIPAA setting strict standards, your data integration must include encryption, access controls, and audit trails to protect sensitive information.
- Latency and Freshness Requirements
Latency and freshness requirements influence whether you choose batch processing, streaming, or hybrid models. Real-time insights demand faster, more responsive architectures.
- Data Lineage and Observability
Data lineage and observability are vital for trust and troubleshooting. Knowing where data comes from, how it’s transformed, and where it ends up improves governance and supports faster issue resolution.
Cloud vs. On-Premise Integration Architecture
Choosing between cloud-based and on-premise data integration architecture is one of the first strategic decisions organizations face. Each approach offers unique advantages depending on business needs, regulatory requirements, and technical resources.
Advantages of Cloud-Based Integration
Cloud-based integration solutions offer unmatched scalability, flexibility, and speed to deploy. Platforms like AWS Glue, Azure Data Factory, and Google Cloud Dataflow allow businesses to ingest, process, and distribute data across global systems without worrying about underlying hardware. With pay-as-you-go pricing, organizations can better manage costs, scaling resources up or down based on actual usage.
Security in the cloud has also matured significantly. Major providers comply with frameworks like GDPR, HIPAA, and SOC 2, offering advanced encryption and identity management features out-of-the-box. Furthermore, cloud-native architectures often come with built-in support for real-time streaming, API-led integration, and automated orchestration.
Hybrid Models and Migration Paths
For many organizations, moving entirely to the cloud isn’t feasible immediately. Hybrid integration models—where some systems remain on-premise while others operate in the cloud—allow gradual migration. Hybrid approaches help businesses modernize without disrupting mission-critical legacy systems.
Multi-Cloud and Vendor-Agnostic Designs
Today, many companies pursue multi-cloud or vendor-agnostic architectures to avoid lock-in risks. By building flexibility into the data integration layer, businesses can switch providers or use best-of-breed services across AWS, Azure, GCP, and beyond, ensuring resilience, competitive pricing, and broader service capabilities.
Role of AI and Automation in Data Integration
As data volumes grow and systems become more complex, AI and automation are playing an increasingly vital role in shaping modern data integration architecture. These technologies help organizations handle data faster, with greater accuracy, and with significantly less manual effort.
AI in Data Mapping and Transformation
One major area where AI contributes is in intelligent data mapping and transformation. Instead of manually defining complex rules to connect different source systems, AI algorithms can now automatically detect relationships between datasets, recommend mappings, and even suggest transformations. According to a recent study by Gartner, AI-driven solutions can reduce data integration time by up to 50%, speeding up projects and significantly lowering human error.
Automation in Data Ingestion and Workflow Management
Automation enhances the data ingestion layer by orchestrating routine tasks like data extraction, cleansing, enrichment, and loading. Automated workflows ensure that real-time and batch processes run seamlessly without constant human supervision. This improves consistency, reduces bottlenecks, and ensures smoother operation across the data integration flow diagram. A Forrester report showed that companies using automation for their data workflows report a 40% reduction in operational costs.
AI-Driven Monitoring and Anomaly Detection
AI also shines in monitoring and anomaly detection. Advanced systems can automatically identify irregularities, flag failed data pipelines, and even suggest fixes before these issues impact downstream processes. For instance, machine learning models can predict potential data failures before they occur, enabling proactive solutions that save both time and money.
Tools and Technologies to Consider
Building a reliable and scalable data integration architecture often depends on selecting the right tools. From ETL processes to metadata management, various technologies help streamline integration efforts and improve efficiency across the entire data pipeline.
ETL Tools – Talend, Informatica, Apache NiFi
ETL tools form the foundation of many integration strategies. Platforms like Talend and Informatica offer robust solutions for extracting, transforming, and loading data across different systems, supporting both batch and real-time workflows. Apache NiFi, an open-source option, is popular for its visual flow-based programming, making it easier to design, monitor, and manage complex data integration flow diagrams.
Cloud Platforms – Snowflake, BigQuery, Redshift
Modern cloud platforms such as Snowflake, Google BigQuery, and Amazon Redshift provide powerful data storage layers. They support elastic scalability, strong security features, and built-in optimization for querying and reporting, making them ideal choices for organizations moving toward cloud-native architectures.
Orchestration – Airflow, Dagster
For managing complex data workflows, orchestration tools like Apache Airflow and Dagster are essential. They enable teams to schedule, monitor, and automate multi-step processes, ensuring data pipelines run smoothly from ingestion to final delivery.
Integration Platforms – MuleSoft, Apache Kafka, Fivetran
When connecting diverse systems, integration platforms like MuleSoft offer comprehensive API-led connectivity, while Apache Kafka specializes in real-time event streaming. Fivetran focuses on automating data pipeline creation, making ingestion fast and low-maintenance.
Metadata & Governance – Collibra, Alation
Collibra and Alation are leading platforms for metadata management and governance. They help catalog datasets, track data lineage, and ensure compliance, supporting better data stewardship and trust across the organization.
Modern Data Integration Architecture – Essential Takeaways
Modern data integration architecture defines how data is ingested, transformed, governed, and delivered across systems in real time or batches. By leveraging cloud-native platforms, ETL/ELT pipelines, APIs, automation, and AI-driven monitoring, organizations can eliminate data silos, improve data quality, and enable scalable analytics. A well-designed architecture supports faster decision-making, regulatory compliance, and future-ready data strategies.
Final Words
A well-designed data integration architecture is key to ensuring seamless, secure, and scalable data flow across systems. As businesses move toward real-time, cloud-native environments, having the right framework and tools becomes essential. If you’re ready to optimize your data strategy, Folio3 Data Services offers tailored solutions to help you build, modernize, and automate your integration processes.
Connect with Folio3’s expert team today to unlock the full potential of your data!



