

We are a part of a world where data powers everything from personalized recommendations to predictive healthcare, big data pipelines have become indispensable for organizations seeking to transform raw data into actionable insights. But building a robust, efficient, and scalable big data pipeline demands more than just technology.
It requires an intricate architecture, precise processes, and the capability to handle vast and diverse data sources. In this guide, we’ll break down the essentials of big data pipelines, explore key architectural considerations, and examine how different industries use these pipelines for data-driven success.
What is a Big Data Pipeline?
A big data pipeline is a comprehensive system that manages the continuous flow of data from multiple sources to a centralized data platform, making the data readily available for analysis. This end-to-end pipeline captures raw data from various sources, including IoT devices, social media, application logs, and business transactions.
It then moves through stages of processing and transformation, which prepares the data for insights, whether for real-time applications or historical analysis. By transforming raw data into structured, valuable information, big data pipelines support speed, scalability, and flexibility—essential components in today’s data-driven landscape.
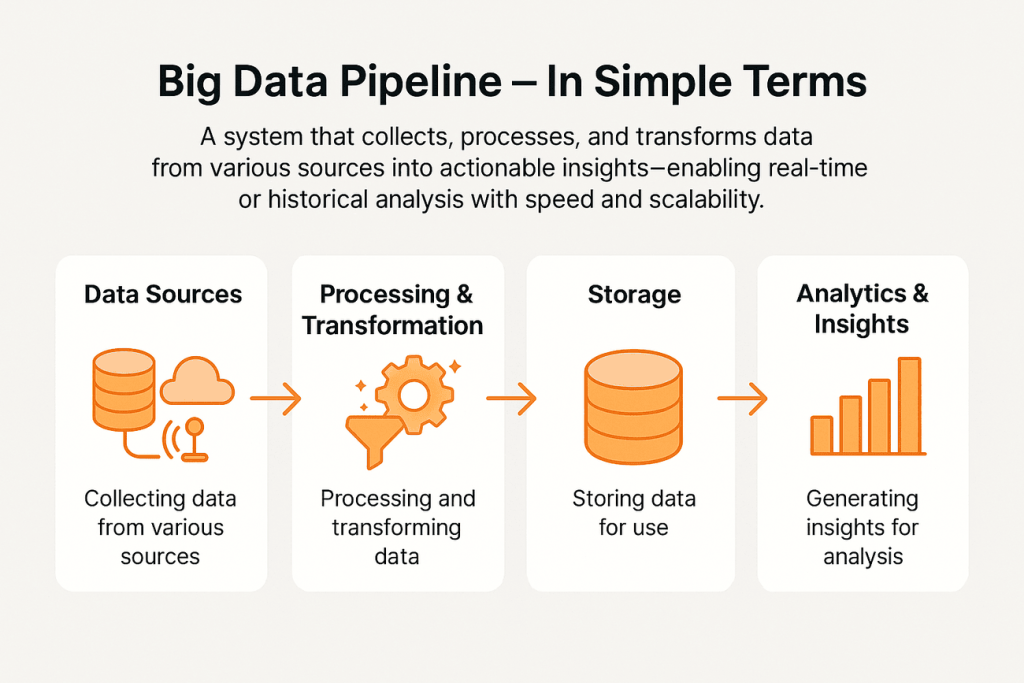
Importance of Big Data Pipelines in Modern Data Processing
The ability to handle massive and diverse data types is one of the most significant advantages of big data pipelines, especially within data engineering consulting services. In industries ranging from finance to healthcare and retail, these pipelines gather data from multiple, often disparate sources, processing it in real-time to generate meaningful insights. For example, a retail business can use a big data pipeline to track and analyze sales and inventory, allowing it to optimize stock levels and personalize customer experiences instantly.
For example, a retail business can use a big data pipeline to track and analyze sales and inventory, allowing it to optimize stock levels and personalize customer experiences instantly.
The real-time capabilities of a well-designed pipeline give businesses the edge to act on insights as they arise, enabling proactive decision-making, improving customer satisfaction, and identifying opportunities or risks promptly.
Thus, big data pipelines play a crucial role in modern data processing by allowing organizations to make data-informed decisions faster, adapt to shifting market demands, and ultimately achieve greater operational efficiency.
Components of a Big Data Pipeline
A big data pipeline consists of several crucial components that work together to ensure the smooth movement, processing, and analysis of data. Each step builds on the previous one, creating an efficient and scalable system capable of managing vast data volumes in real time. This big data implementation approach ensures that the entire pipeline can accommodate new data sources and growing demands.
Here’s a closer look at the essential big data pipeline components:
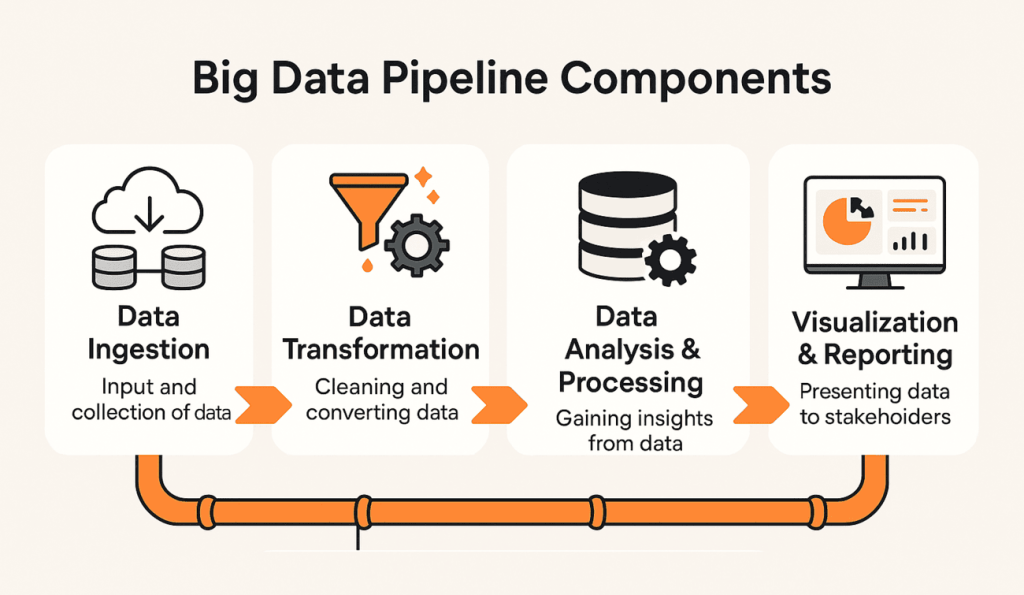
1. Data Ingestion: Collecting Data from Diverse Sources
Data ingestion is the foundational step of a big data pipeline. It involves collecting data from a multitude of sources such as application logs, databases, IoT devices, social media platforms, and external APIs. The goal is to consolidate this data into a single platform, creating a unified view that enables easy access and analysis. When evaluating options, a big data platform comparison can help determine the best technology for specific data sources and real-time needs.
- Diverse Data Sources: Big data pipelines can pull in structured data (e.g., SQL databases), semi-structured data (e.g., JSON files from APIs), and unstructured data (e.g., social media posts and multimedia content).
- Real-time and Batch Processing: Depending on business needs, data ingestion can occur in real-time for instant processing or in batches to handle larger volumes periodically.
2. Data Transformation: Cleaning, Structuring, and Enriching Data
Once data is ingested, it needs transformation to ensure it’s clean, consistent, and suitable for analysis. This process includes removing errors, standardizing formats, and enriching data by combining it with additional information from other sources, enhancing its context and usability.
- Cleaning: Removing duplicates, correcting errors, and handling missing values help make the data reliable.
- Structuring and Normalizing: Ensuring data follows a consistent format (e.g., standardizing date formats or unit measurements) to support smooth analysis.
- Enrichment: Integrating external data sources like demographic information or industry benchmarks to add value and depth to raw data.
3. Data Storage: Reliable and Scalable Storage Solutions
After ingestion and transformation, the data must be stored in a manner that ensures durability, scalability, and easy retrieval. Big data storage solutions like Amazon S3, Google Cloud Storage, and HDFS (Hadoop Distributed File System) provide the infrastructure needed to handle large-scale datasets. Organizations often undergo data warehouse to data lake migration to optimize their storage solutions, especially for unstructured and semi-structured data.
- Scalability: Storage solutions for big data pipelines must support growth, as data volumes tend to expand rapidly.
- Data Retrieval and Management: Storage systems should offer flexible retrieval options to accommodate different data access needs, from fast real-time queries to deeper, more complex analyses.
4. Data Analysis and Processing: Deriving Insights and Running Computations
Data analysis and processing are core components that transform stored data into actionable insights. Using processing tools like Apache Spark or Apache Flink, businesses can conduct batch analysis on historical data or real-time analysis on streaming data, depending on the requirements.
- Real-time Processing: Allows for near-instant analysis, which can be critical for applications requiring immediate insights (e.g., fraud detection).
- Batch Processing: Suitable for large datasets where instant feedback isn’t required, such as monthly sales analysis.
- Advanced Analytics: Incorporating machine learning and big data predictive analytics can offer insights into future trends, customer behavior, or risk assessment.
5. Data Visualization and Reporting: Presenting Results to Stakeholders
The final step in a big data pipeline is presenting insights through data visualization and reporting, making data understandable and actionable for decision-makers. Tools like Tableau, Power BI, and Looker help create charts, graphs, and dashboards that translate complex data into digestible visuals for stakeholders.
- Visual Storytelling: Presenting data insights in a compelling way helps stakeholders quickly grasp trends, outliers, and opportunities.
- Customizable Dashboards: Allow stakeholders to interact with data, exploring different variables and gaining insights relevant to their specific roles or departments.
Big Data Pipeline Architecture
The architecture of a big data pipeline determines its efficiency, flexibility, and ability to scale with the growing demands of data processing. A well-designed architecture, often influenced by data strategy consultation, balances multiple types of data processing while ensuring reliability and performance.
Let’s break down the types of data processing architectures and key design considerations for building a robust big data pipeline.
Types of Data Processing Architectures
1. Batch Processing: Processing Large Batches of Data
- Overview: Batch processing is designed for processing large datasets in bulk at scheduled intervals, such as hourly, daily, or monthly. It is particularly suitable for tasks that don’t require immediate results, making it an excellent choice for historical data analysis and periodic reporting.
- Use Cases: Examples include monthly financial reporting, end-of-day data consolidation, and historical data analysis.
- Advantages: Batch processing is highly efficient for processing substantial volumes of data and can be scheduled during off-peak hours to reduce system strain. Organizations often pair batch architectures with data lake consulting services to design scalable storage and processing strategies for these large datasets.
2. Stream Processing: Handling Real-Time Data Streams
- Overview: Stream processing handles continuous data flows in real-time or near-real-time, allowing systems to react immediately to new data. This architecture is essential for applications where instant insights are necessary, such as monitoring customer activity or detecting fraudulent transactions.
- Use Cases: Fraud detection in financial transactions, real-time customer behavior analysis, IoT sensor data monitoring, and social media trend tracking.
- Advantages: Stream processing provides immediate insights, helping organizations respond swiftly to dynamic data, especially in industries where real-time analysis is crucial.
3. Hybrid Processing: Combining Batch and Stream for Flexibility
- Overview: Hybrid processing architectures enable organizations to use both batch and stream processing within the same pipeline, offering a flexible approach for different data types and requirements. As part of modern data pipeline architectures, this model allows teams to manage real-time data for immediate insights while still processing large data batches for in-depth analysis.
- Use Cases: A common example of big data in the retail industry is using hybrid processing to analyze both real-time customer interactions for personalized recommendations and historical data for inventory forecasting.
- Advantages: Hybrid architectures bring the best of both worlds, providing flexibility for organizations to process data in real time and in bulk, depending on specific needs.
Comparison of Data Processing Architectures
| Type | Overview | Use Cases | Advantages |
|---|---|---|---|
| Batch Processing | Processes large volumes of data at scheduled intervals (e.g., hourly, daily, monthly). | – Monthly financial reports – End-of-day data consolidation – Historical data analysis | – Efficient for large datasets – Can run during off-peak hours – Ideal for non-urgent tasks |
| Stream Processing | Handles continuous, real-time data flows for immediate insights and reactions. | – Fraud detection – Real-time customer behavior tracking – IoT sensor monitoring – Social media trend analysis | – Provides instant insights – Enables real-time response – Crucial for time-sensitive use cases |
| Hybrid Processing | Combines batch and stream processing in one architecture for maximum flexibility. | – Real-time customer personalization + inventory forecasting – Multi-layer retail analytics | – Supports both real-time and bulk needs – Adaptable to diverse data sources – Scalable and flexible |
Design Considerations for Scalability and Reliability
1. Ensuring Fault Tolerance and Data Redundancy
- Fault Tolerance: A fault-tolerant system can continue functioning even if individual components fail. Techniques like replication and automated recovery help prevent disruptions in the pipeline, allowing data processing to continue uninterrupted.
- Data Redundancy: Implementing data redundancy by storing multiple copies of data ensures that data loss is minimized and consistency is maintained. In distributed systems, redundancy is particularly vital to avoid loss of valuable insights.
2. Implementing Horizontal Scaling for Increased Data Loads
- Horizontal Scaling: Horizontal scaling allows an architecture to handle increasing data loads by adding more nodes to the system rather than increasing the power of a single node. This design is essential for big data pipelines as data volumes grow, enabling the system to handle more traffic and maintain performance.
- Benefits: Horizontal scaling offers a cost-effective way to grow capacity, supporting additional data sources and handling more complex workloads without overloading existing infrastructure.
3. Optimizing for Low Latency and High Throughput
- Low Latency: Reducing latency, or the time it takes for data to travel through the pipeline, is critical in applications requiring timely responses. Optimizing for low latency ensures that insights are generated with minimal delay, enhancing the responsiveness of real-time systems.
- High Throughput: High throughput is achieved by maximizing the volume of data the system can process within a specific timeframe. This is crucial for pipelines handling vast datasets or streaming data, ensuring that data processing keeps pace with incoming information.
- Implementation: By balancing efficient data partitioning, resource allocation, and parallel processing, organizations can achieve the high throughput and low latency needed to maintain reliable, timely insights as data demands continue to grow.
FAQs
What are the key components of a big data pipeline?
The main components of a big data pipeline include:
- Data ingestion (collecting raw data)
- Data transformation (cleaning and enriching data)
- Data storage (reliable and scalable storage solutions)
- Data processing and analysis (batch or real-time computation)
- Data visualization and reporting (insight presentation for stakeholders)
What industries benefit the most from big data pipelines?
Industries like finance, healthcare, retail, manufacturing, and logistics benefit greatly. For instance, retailers use pipelines for real-time inventory management, while healthcare providers use them to monitor patient data and predict outcomes.
What tools are commonly used in big data pipeline architecture?
Popular tools include:
- Apache Kafka or Flume for data ingestion
- Apache Spark, Flink, or Beam for processing
- Amazon S3, HDFS, or Google Cloud Storage for data storage
- Tableau, Power BI, and Looker for visualization
How can businesses get started with building a big data pipeline?
Businesses can start by:
- Identifying data sources and objectives
- Choosing the right tools and architecture (batch, stream, or hybrid)
- Ensuring the pipeline is scalable, reliable, and secure
- Partnering with data engineering experts like Folio3 to design and implement end-to-end big data solutions tailored to business goals.
Final Words
Transforming data into actionable insights requires a combination of structured pipelines, advanced technology, and expert guidance. Big data pipelines are essential for proactive decision-making, enhancing customer experiences, and maintaining a competitive edge. Yet, building and maintaining these pipelines can be complex and resource-intensive.
This is where Folio3’s Data Services come in. With extensive experience in big data, cloud integration, and data engineering, Folio3 provides tailored solutions that help businesses leverage their data to its fullest potential. From building scalable big data pipelines to implementing cloud-based data processing solutions, Folio3’s services are designed to streamline data workflows, boost efficiency, and drive growth.



